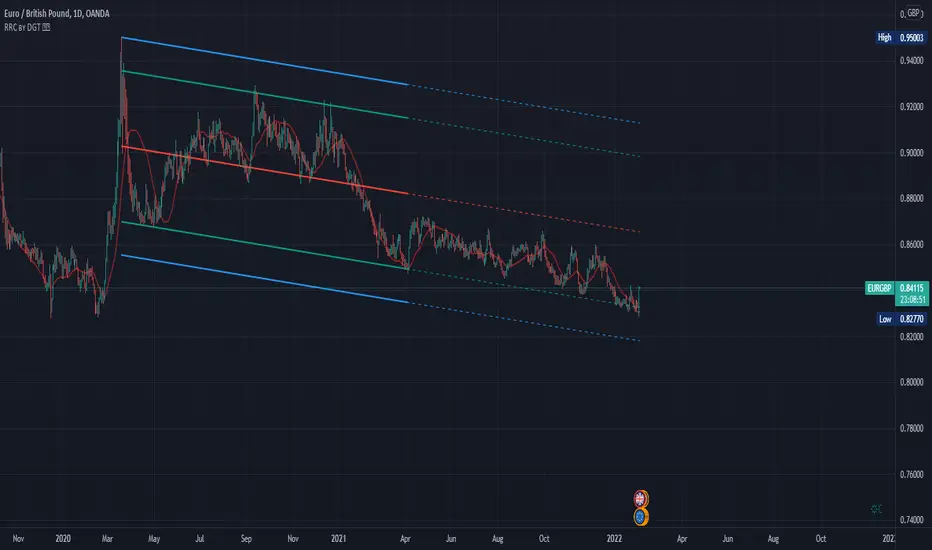
Raff Regression Channel by DGTRᴀꜰꜰ Rᴇɢʀᴇꜱꜱɪᴏɴ Cʜᴀɴɴᴇʟ (RRC)
This study aims to automate Raff Regression Channel drawing either based on ZigZag Indicator or optionally User Preference
The Raff Regression Channel , developed by Gilbert Raff, is based on a linear regression, which is the least-squares line-of-best-fit for a price series, with evenly spaced trend lines above and below . The width of the channel is set by determining the high or low that is the furthest from the linear regression.
Because the channel distance is based off the largest pullback or highest peak within a trend, for effectively drawing and using a Raff Regression Channel it is recommend/required that a Raff Regression Channel is applied to “mature” trends. Knowing this requirement, for better automated drawing results this study benefits from the Zig Zag Indicator, where the Zig Zag indicator is used to help identify price trends and changes in price trends. Option to manually adjust lengths for drawing a Raff Regression Channel is also made available.
Using a Raff Regression Channel
Once The Raff Regression Channel is drawn, covering an existing trend, Exᴛᴇɴꜱɪᴏɴ Lɪɴᴇꜱ are drawn to identify ᴛʜᴇ ꜱᴜᴘᴘᴏʀᴛ﹐ʀᴇꜱɪꜱᴛᴀɴᴄᴇ ᴏʀ ʀᴇᴠᴇʀꜱᴀʟ ᴘᴏɪɴᴛꜱ
The trend is up as long as prices rise within this channel. An uptrend may be reversing (not always, but likely) when price breaks below the channel extension . The trend is down as long as prices decline within the channel. Similarly, a downtrend may be reversing (not always, but likely) when price breaks above the channel extension . Moves outside the channel extensions can be indication of a reversal or can denote overbought or oversold conditions
For further details please refer to education post Raff Regression Channel
█ FEATURES
- AUTO or MANUALLY adjusted Raff Regression Channel and Channel Extentions drawing
- ALERTs, for Linear Regression Line, Raff Regression Upper and Lower Channel Extentions
- LSMA , Least Squares Moving Average, in other words Linear Regression Curve
█ SETTINGS
Setting Loopback and Number of Bars are the most important part for The Raff Regression Channel, where ;
- Lookback, defines where the Raff Regression Channel is starting, it is recommended to set to a trend begining
- Number of Bars, defines how many bars to be assumed for calculation, or simply stated the end of the Raff Regression Channel drawing (not extentions but the main channel, extentions by default will be drawn till the last bar)
Setting of Loopback and Number of Bars is performed eigher automatically based on Zig Zag indicator or users may prefer to set them manually. If selected automatically then
- Deviation and Depth values of Zig Zag indicator are used for calculations (enabling visually plotting of ZigZag Lines will help to identify better visually the points), where ;
Deviation, is a multiplier that affects how much the price should deviate from the previous pivot in order for the bar to become a new pivot.
Depth, affects the minimum number of bars that will be taken into account when building
Short-term traders may wish to apply the channel to small waves of a trend so they can reduce the value of the Deviation and Depth
█ OTHER CHANNEL CONSEPTS
Linear Regression Channels, , what linear regression channels are? and linear regression channel/curve/slope study
Fibonacci Channels, how to apply fibonacci channels and automated fibonacci channels study
Andrews’ Pitchfork, how to apply pitchfork and automated pitchfork study
Special Thanks to @Kiss66000 for his kind suggestion, je vous remercie beaucoup @Kiss66000
Disclaimer :
Trading success is all about following your trading strategy and the indicators should fit within your trading strategy, and not to be traded upon solely
The script is for informational and educational purposes only. Use of the script does not constitute professional and/or financial advice. You alone have the sole responsibility of evaluating the script output and risks associated with the use of the script. In exchange for using the script, you agree not to hold dgtrd TradingView user liable for any possible claim for damages arising from any decision you make based on use of the script
Regressão Linear
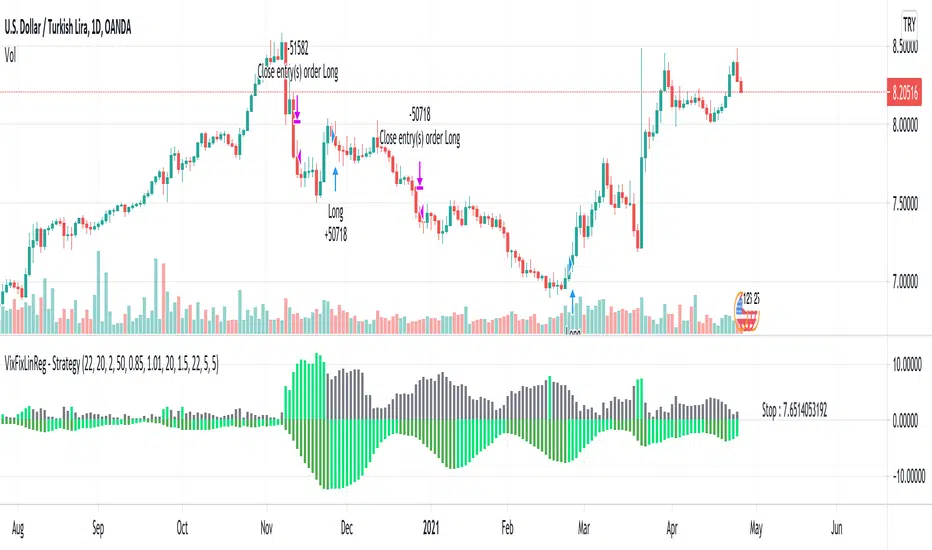
VixFixLinReg-IndicatorSame as VixFixLinearRegression strategy published earlier - but as indicator for those who want to use it as indicator.
Strategy can be found here:
Concept is simple:
Based on VixFix script by Chris Moody. VIX-Fix can sometime give early signal. Hence, apply linear regression for better estimation of market bottom. Area above 0 shows VixFix whereas the below 0 area is linear regression of VixFix. To estimate market bottom:
First wait for VixFix to turn lime
Then wait for linear regression to turn lime from green.
VixFix may no longer be lime by linear regression chages. But, that's ok.
Have also added option candle color to highlight bottom and alert condition for those who want to use it.

VixFixLinReg-StrategyThis idea came up while discussing about strategies with one of the trading enthusiast from tradingview community.
Strategy basically uses existing script of Vix Fix by Chris Moody:
VixFix is a great indicator for finding the market bottoms. But, sometimes it generates signal too early. But, we can apply linear regression on vix fix to find vix fix top to make timing much better.
Entry condition:
Wait for Vix fix bar to turn lime.
Once vix fix is turned lime, then wait for linear regression (shown below 0) to turn lime from green. This indicates VIX-Fix has started declining.
Go long once above two conditions are satisfied
Exit Condition:
ATR Based Stop
Applied only if linear regression is green - which means VixFix rising.
Note: This is ideal for identifying market bottom. May not yield good results on individual stocks.
Linear Regression Channel / Curve / Slope by DGTTʜᴇ Lɪɴᴇᴀʀ Rᴇɢʀᴇꜱꜱɪᴏɴ Cʜᴀɴɴᴇʟꜱ
Linear Regression Channels are useful measure for technical and quantitative analysis in financial markets that help identifying trends and trend direction. The use of standard deviation gives traders ideas as to when prices are becoming overbought or oversold relative to the long term trend
The basis of a linear regression channel
Linear Regression Line – is a line drawn according to the least-squares statistical technique which produces a best-fit line that cuts through the middle of price action, a line that best fits all the data points of interest. The resulting fitted model can be used to summarize the data, to predict unobserved values from the same system. Linear Regression Line then present basis for the channel calculations
The linear regression channel
2. Upper Channel Line – A line that runs parallel to the Linear Regression Line and is usually one to two standard deviations above the Linear Regression Line.
3. Lower Channel Line – This line runs parallel to the Linear Regression Line and is usually one to two standard deviations below the Linear Regression Line.
Unlike Fibonacci Channels and Andrew’s Pitchfork, Linear Regression Channels are calculated using statistical methods, both for the regression line (as expressed above) and deviation channels. Upper and Lower channel lines are presenting the idea of bell curve method, also known as a normal distribution and are calculated using standard deviation function.
A standard deviation include 68% of the data points, two standard deviations include approximately 95% of the data points and any data point that appears outside two standard deviations is very rare.
It is often assumed that the data points will move back toward the average, or regress and channels would allow us to see when a security is overbought or oversold and ready to revert to the mean
please note : Over time, the price will move up and down, and the linear regression channel will experience changes as old prices fall off and new prices appear
█ Linear Regression Study Features
Linear Regression Channel
- Linear regression line as basis
- Customizable multiple channels based on Standard Deviation
- ALERTs for the channel levels
Linear Regression Curve
- Linear regression curve as basis
- Optional : Bands based on Standard Deviation or Volatility (ATR). Bands are applied with fixed levels 1, 2 and 3 times StdDev or ATR away from the curve
Linear Regression Slope
- Optional : Up/Down slope arrows for a used defined period
█ Volume / Volatility Add-Ons
High Volatile Bar Indication
Volume Spike Bar Indication
Volume Weighted Colored Bars
Body/Wick to Range Osc.This script is meant to be a form of pure candlestick analysis.
Terminology in the description used below is as follows:
- numcands = Number of candles specified by the user to be used for sampling in each moving average.
This script plots moving average (SMA/EMA specified by the user ) of the percentage of the high-low range that the previous {numcands} candles the upper wicks, lower wicks, and the body take up.
The user may specify if the absolute value of the body percentage is to be used (true by default). To account for this, a horizontal line is also plotted at 0 to show when the body percentage moves above or below 0.
The values that all of these moving averages plotted will oscillate between 0 and 1 (-1 and 1 for the body percentage if the absolute value of candles is not used).
Other notes: The user may select the colors used (colorblind support, as the defaults are red and green). Cross overs and cross unders are accounted for in alertconditions (as is if the body % moves above and below 0% if absolute values are not used).
An interpretation of the use of this script may be: If the upper wicks begin to take up a larger portion of the high-low range, it may signal downward selling pressure (and vise-versa for lower wicks). However, this may be open to interpretation based upon the specified {numcands} used.
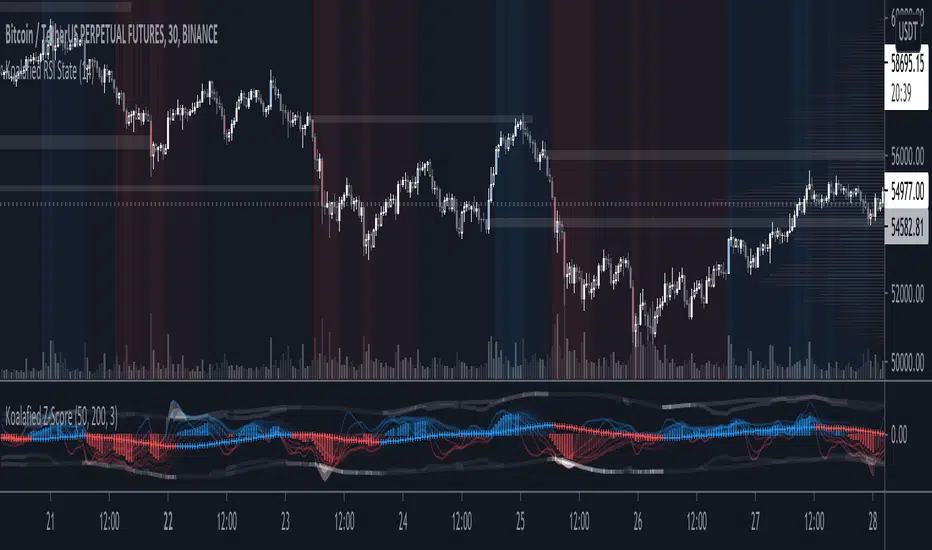
Koalafied Z-ScoreZ-Score indicator derived from Pecker's previously released indicators (Percentile and PPO Fishnet). Includes linear regression bands weighted by volume/volatility.
Quad MAFor a dive into the fine details, see the source code/documentation.
Quad MA is a program designed to allow a wide range of flexibility in overlaying multiple moving averages onto a chart.
This program handles the ability to:
- Overlay Up to 4 moving averages on the chart.
- Change the length of each moving average.
- Adjust optional values for special moving averages
(least squares and Arnaud Legoux)
- Change the color for each moving average.
- Change the type of each moving average individually.
- Change the visibility of each moving average.
- Change the source of the moving averages.
- Set alerts for a cross between any two moving averages.

Parallel Pivot Lines [LuxAlgo]Displays lines connecting past pivot high/low points with each line having the slope of a linear regression. This slope can also be controlled by the user with the 'Slope' setting. Each line can be used as a support or resistance by the user.
Settings
Length : Pivot length. Use higher values for having lines connected to more significant pivots points.
Lookback : Number of lines connecting a pivot high/low to display, with a total of lines equal to Lookback*2
Slope : Allows the user to multiply the linear regression slope by a number within -1 and 1
Limitations
The script has currently several real time behavior limitations. Lines are displayed retrospectively and will not update with the arrival of new bars. Readjusting the indicator to newer pivots will require the user to either hide/unhide the indicator or change its settings.
High Length or Lookback values might not return any lines if the location of a pivot point is outside the defined buffer size of the indicator (set as 5000 bars).
How To Use
The indicator can be used to get supports and resistances and is more so closer to a drawing tool due to its limitations. The lines not updating with the arrival of new bars have the advantage of providing fixed supports/resistances.
The Slope setting allows the user to control the angle and direction of the lines. Using a Slope of 1 will return lines with the same slope as the one of a linear regression fit from the farthest pivot point displayed by the indicator to the most recent bar.
The chart above shows the indicators and a linear regression in orange.
If you want to have horizontal lines, use a Slope equal to 0.
Finally using a negative slope value will allow the user to have lines in opposite directions to the main trend.
Conclusion
We hope you like this indicator (drawing tool) and find it useful for drawing your support & resistances in a unique way!

Robust Channel [tbiktag]Introducing the Robust Channel indicator.
This indicator is based on a remarkable property of robust statistics , namely, the resistance to the presence of data points that deviate significantly from the established trend (generally speaking, outliers ). Being outlier-resistant, the Robust Channel indicator “remembers” a pre-existing trend and thus exhibits a very peculiar "lag" in case of a sharp price change. This allows high-confidence identification of such price actions as a trend reversal, range break, pullback, etc.
In the case of trending and range-bound market conditions, the price remains within the channel most of the time, fluctuating around the central line.
Technical details
The central line is calculated using the repeated median slope algorithm. For each data point in a lookback window of a user-specified Length , this method calculates the median slope of the lines that connect that point to all other points inside the window. The overall median of these median slopes is then calculated and used as an estimate of the trend slope. The algorithm is very efficient as it uses an on-the-fly procedure to update the array containing the slopes (new data pushed - old data removed).
The outer line is then calculated as the central line plus the Length -period standard deviation of the price data multiplied by a user-defined Channel Width Factor . The inner line is defined analogously below the central line.
Usage
As a stand-alone indicator, the Robust Channel can be applied similarly to the Bollinger Bands and the Keltner Channel:
A close above the outer line can be interpreted as a bullish signal and a close below the inner line as a bearish signal.
Likewise, a return to the channel from below after a break may serve as a bullish signal, while a return from above may indicate bearish sentiment.
Robust Channel can be also used to confirm chart patterns such as double tops and double bottoms.
If you like this indicator, feel free to leave your feedback in the comments below!

Matrix Library (Linear Algebra, incl Multiple Linear Regression)What's this all about?
Ever since 1D arrays were added to Pine Script, many wonderful new opportunities have opened up. There has been a few implementations of matrices and matrix math (most notably by TradingView-user tbiktag in his recent Moving Regression script: ). However, so far, no comprehensive libraries for matrix math and linear algebra has been developed. This script aims to change that.
I'm not math expert, but I like learning new things, so I took it upon myself to relearn linear algebra these past few months, and create a matrix math library for Pine Script. The goal with the library was to make a comprehensive collection of functions that can be used to perform as many of the standard operations on matrices as possible, and to implement functions to solve systems of linear equations. The library implements matrices using arrays, and many standard functions to manipulate these matrices have been added as well.
The main purpose of the library is to give users the ability to solve systems of linear equations (useful for Multiple Linear Regression with K number of independent variables for example), but it can also be used to simulate 2D arrays for any purpose.
So how do I use this thing?
Personally, what I do with my private Pine Script libraries is I keep them stored as text-files in a Libraries folder, and I copy and paste them into my code when I need them. This library is quite large, so I have made sure to use brackets in comments to easily hide any part of the code. This helps with big libraries like this one.
The parts of this script that you need to copy are labeled "MathLib", "ArrayLib", and "MatrixLib". The matrix library is dependent on the functions from these other two libraries, but they are stripped down to only include the functions used by the MatrixLib library.
When you have the code in your script (pasted somewhere below the "study()" call), you can create a matrix by calling one of the constructor functions. All functions in this library start with "matrix_", and all constructors start with either "create" or "copy". I suggest you read through the code though. The functions have very descriptive names, and a short description of what each function does is included in a header comment directly above it. The functions generally come in the following order:
Constructors: These are used to create matrices (empy with no rows or columns, set shape filled with 0s, from a time series or an array, and so on).
Getters and setters: These are used to get data from a matrix (like the value of an element or a full row or column).
Matrix manipulations: These functions manipulate the matrix in some way (for example, functions to append columns or rows to a matrix).
Matrix operations: These are the matrix operations. They include things like basic math operations for two indices, to transposing a matrix.
Decompositions and solvers: Next up are functions to solve systems of linear equations. These include LU and QR decomposition and solvers, and functions for calculating the pseudo-inverse or inverse of a matrix.
Multiple Linear Regression: Lastly, we find an implementation of a multiple linear regression, including all the standard statistics one can expect to find in most statistical software packages.
Are there any working examples of how to use the library?
Yes, at the very end of the script, there is an example that plots the predictions from a multiple linear regression with two independent (explanatory) X variables, regressing the chart data (the Y variable) on these X variables. You can look at this code to see a real-world example of how to use the code in this library.
Are there any limitations?
There are no hard limiations, but the matrices uses arrays, so the number of elements can never exceed the number of elements supported by Pine Script (minus 2, since two elements are used internally by the library to store row and column count). Some of the operations do use a lot of resources though, and as a result, some things can not be done without timing out. This can vary from time to time as well, as this is primarily dependent on the available resources from the Pine Script servers. For instance, the multiple linear regression cannot be used with a lookback window above 10 or 12 most of the time, if the statistics are reported. If no statistics are reported (and therefore not calculated), the lookback window can usually be extended to around 60-80 bars before the servers time out the execution.
Hopefully the dev-team at TradingView sees this script and find ways to implement this functionality diretly into Pine Script, as that would speed up many of the operations and make things like MLR (multiple linear regression) possible on a bigger lookback window.
Some parting words
This library has taken a few months to write, and I have taken all the steps I can think of to test it for bugs. Some may have slipped through anyway, so please let me know if you find any, and I'll try my best to fix them when I have time to do so. This library is intended to help the community. Therefore, I am releasing the library as open source, in the hopes that people may improving on it, or using it in their own work. If you do make something cool with this, or if you find ways to improve the code, please let me know in the comments.

Linear Regression CandlesThere are many linear regression indicators out there, most of them draw lines or channels, but this one actually draws a chart.
Repeated Median Regression ChannelThis script uses the Repeated Median (RM) estimator to construct a linear regression channel and thus offers an alternative to the available codes based on ordinary least squares.
The RM estimator is a robust linear regression algorithm. It was proposed by Siegel in 1982 (1) and has since found many applications in science and engineering for linear trend estimation and data filtering.
The key difference between RM and ordinary least squares methods is that the slope of the RM line is significantly less affected by data points that deviate strongly from the established trend. In statistics, these points are usually called outliers, while in the context of price data, they are associated with gaps, reversals, breaks from the trading range. Thus, robustness to outlier means that the nascent deviation from a predetermined trend will be more clearly seen in the RM regression compared to the least-squares estimate. For the same reason, the RM model is expected to better depict gaps and trend changes (2).
Input Description
Length : Determines the length of the regression line.
Channel Multiplier : Determines the channel width in units of root-mean-square deviation.
Show Channel : If switched off , only the (central) regression line is displayed.
Show Historical Broken Channel : If switched on , the channels that were broken in the past are displayed. Note that a certain historical broken channel is shown only when at least Length / 2 bars have passed since the last historical broken channel.
Print Slope : Displays the value of the current RM slope on the graph.
Method
Calculation of the RM regression line is done as follows (1,3):
For each sample point ( t (i), y (i)) with i = 1.. Length , the algorithm calculates the median of all the slopes of the lines connecting this point to the other Length -1 points.
The regression slope is defined as the median of the set of these median slopes.
The regression intercept is defined as the median of the set { y (i) – m * t (i)}.
Computational Time
The present implementation utilizes a brute-force algorithm for computing the RM-slope that takes O ( Length ^2) time. Therefore, the calculation of the historical broken channels might take a relatively long time (depending on the Length parameter). However, when the Show Historical Broken Channel option is off, only the real-time RM channel is calculated, and this is done quite fast.
References
1. A. F. Siegel (1982), Robust regression using repeated medians, Biometrika, 69 , 242–244.
2. P. L. Davies, R. Fried, and U. Gather (2004), Robust signal extraction for on-line monitoring data, Journal of Statistical Planning and Inference 122 , 65-78.
3. en.wikipedia.org

Moving Regression Band Breakout strategyFollowing the introduction of the Moving Regression Prediction Bands indicator (see link below), I'd like to propose how to utilize it in a simple band breakout strategy :
Go long after the candle closes above the upper band . The lower band (alternatively, the lower band minus the 14-period ATR or the central line ) will serve as a support line .
Exit as soon as the candle closes below the support line .
To manage the risk of false breakouts, a fixed stop loss is set to the value of the support line at the time of opening a position. When the support line moves above the position opening price, shift the stop loss to breakeven.
The same logic but in reverse applies to short positions.
As an option, it is possible to allow long entries only when the slope of the Moving Regression curve is positive (and short entries when the slope is negative).
Model parameters:
Length and Polynomial Order define the lag and smoothness of the model.
Multiplier specifies the width of the channel.
As the default model parameter values, I set those that I found to provide optimal risk / reward ratio on the daily timeframe (for both trending and range-bound market). However, the settings are very flexible and can be well-adjusted to particular market conditions. Feel free to play around and leave feedback in the comments!
Here's the original Moving Regression Prediction Bands script:

Moving Regression Prediction BandsIntroducing the Moving Regression Prediction Bands indicator.
Here I aimed to combine the principles of traditional band indicators (such as Bollinger Bands), regression channel and outlier detection methods. Its upper and lower bands define an interval in which the current price was expected to fall with a prescribed probability, as predicted by the previous-step result of the local polynomial regression (for the original Moving Regression script, see link below).
Algorithm
1. At every time step, the script performs local polynomial regression of the sample data within the lookback window specified by the Length input parameter.
2. The fitted polynomial is used to construct the Moving Regression time series as well as to extrapolate data, that is, to predict the next data point ( MRPrediction ).
3. The accuracy of local interpolation is estimated by means of the root-mean-square error ( RMSE ), that is, the deviation between the fitted polynomial and the observed values.
4. The MRPrediction and RMSE values calculated for the previous bar are then used to build the upper and lower bands , which I define as follows:
Upper Band = MRPrediction_prev + Multiplier *( RMSE_prev )
Lower Band = MRPrediction_prev - Multiplier *( RMSE_prev )
Here the Multiplier is a user-defined parameter that should be interpreted as a quantile in the standard normal distribution (the default value of 2.0 roughly corresponds to the 95% prediction interval).
To visualize the central line , the script offers the following options:
Previous-Period MR Prediction: MRPrediction_prev time series from the above equation.
MR: Conventional Moving Regression time series.
Ribbon: “Previous-Period MR Prediction” and “MR” curves plotted together and colored according to their relative value (green if MR > Previous MR Prediction; red otherwise).
Usage
My original idea was to use the band breakouts as potential trading signals. For example, the price crossing above the upper band is a bullish signal , being a potential sign that price is gaining momentum and is out of a previously predicted trend. The exit signal could be the crossing under the lower band or under the central line.
However, be aware that it is an experimental indicator, so you might fin some better strategies.
Feel free to play around!

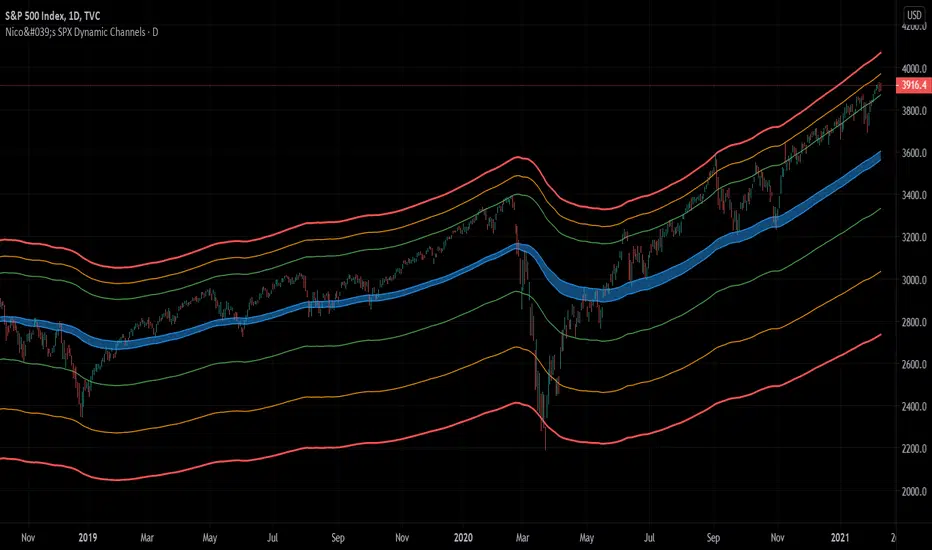
Nico's SPX Dynamic ChannelsTest of dynamic channels and some statistics made by hand.
This indicator was done specifically for the S&P500 index.
As you can see, below the 125 EMA there's a lot more volatility than in the upside. I've made some kind of a dynamic linear regression of the lows and the highs.
I've chosen the MA that best fits the SPX, and then calculated in Excel the percental mean and SDs of most important peaks and valleys that I've chosen in comparison to the 125 MA. This lead to the green, orange and red zones. BUT, I've calculated the peaks and valleys separately, as I assumed that a bear market and crashes have way more volatility than bull markets. That's why the difference between the upper and the lower channels.
The neutral blue zone is composed by an upper EMA of the highs and lower EMA of the lows. No MA in this script uses the close price as a source.
This MA makes sense because it represents a semester of trading, for this particular asset.
Backtest results
It's also interesting to try it here too, as it has a little bit more of data:
SPCFD:SPX
As it's not a trading system, I have no batting average nor ratios for this.
Still, the measures of the peaks and valleys are very accurate and repeat themselves over and over again. The results were:
3rd resistance: 12.88%
2nd resistance: 10.12%
1st resistance: 7.36%
1st support: -6.42%
2nd support: -14.8%
3rd support: -23.18%
All referred to the mean, which is the 125 EMA zone.
After the 1950's works like magic, but not before. You will see that it doesn't work in the great depression and it's crash.
How to use this indicator
Green = First grade support/resistance .
Orange = Second grade support/resistance . Caution.
Red = Third grade support/resistance . High chances of mean reversal.
Blue zone = This is the neutral zone, where the prices are not cheap nor expensive.
Often in a trending market, the price will have the blue zone as it's main support and when trending the price will stick to the green MA.
When the price touches the orange MA, the most probable is that it will return to the green MA.
If the price touches the red zone, there's a high chance that this is a big turning point and it will reverse to the mean (green or blue zone).
Imagine you've bought each time the price touched the red support, check that and you'll start liking this indicator. I think it is a great entry point for investors. The red resistance is good too, but of course it works for a short period of time.
I've backtested this indicator since the beginning of the dataset and it works like magic, but ONLY for the SPX index (spot price).
Leave a comment or some coins if you like it!!!
(I've posted it before like an analysis, not as a script, my bad)
Forecast OscillatorThe Forecast Oscillator is a technical indicator that compares a security close price to its time series forecast. The time series forecast function name is "tsf" and it calculates the projection of the price trend for the next bar.
The Forecast Oscillator and therefore the time series forecast are based on linear regression. The time series forecast indicator is equal to the sum of two other indicators: the linear regression (LinearReg) and the linear regression slope (LinearReg_Slope).
If the Forecast Oscillator stays above the zero line for an extended period, then it signals that the price may rise in the future and if it stays below the zero line for an extended period, then it signals a coming fall in the security price.
The indicator name is "Forecast Oscillator" and it accepts two arguments. The first argument is the time series that is used in the next bar forecast (It is usually the close price) and the second one is the period that will be passed to the time series forecast function during calculation . The technical analysis indicator returns a value in percentage that corresponds to the close price minus the previous value of the time series forecast, multiplied by 100 and divided by the close price.
Author's Note:
Just look at the exaggerated movements of the oscillator especially in trend changes . Some examples can be experienced on the chart in rectangles.
Kıvanç Özbilgiç

Volume-Supported Linear Regression TrendHello Traders,
Linear Regression gives us some abilities to calculate the trend and if we combine it with volume then we may get very good results. Because if there is no volume support at up/downtrends then the trend may have a reversal soon. we also need to check the trend in different periods. With all this info, I developed Volume-Supported Linear Regression Trend script. The script checks linear regression of price and volume and then calculates trend direction and strength.
You have option to set Source, Short-Term Period and Long-Term Period. you can set them as you wish.
By default:
Close is used as "Source"
Short-Term Period is 20
Long-Term Period is 50
in following screenshot I tried to explain short term trend (for uptrend). Volume supports the trend? any volume pressure on trend? possible reversal? same idea while there is downtrend.
in following screenshot I tried to explain long term trend:
You can also check Positive/Negative Divergences to figure out possible reversals (to automate it, you can use Divergence for Many Indicators v4 , it has ability to check divergences on external indicators)
Enjoy!
Theil–Sen EstimatorThe Theil-Sen estimator is a nonparametric statistics method for robustly fitting a regression line to sample points (1,2).
As stated in the Wikipedia article (3), the method is " the most popular nonparametric technique for estimating a linear trend " in the applied sciences due to its robustness to outliers and limited assumptions regarding measurement errors.
Relation with other Methods
The Theil-Sen estimator can be significantly more accurate than simple linear regression (least squares) for skewed and heteroskedastic data.
Method Description
The script computes all the slopes between pairs of points and takes the median as the estimate of the regression slope, m . Subsequently, the intercept, b , is determined from the sample points as the median of y(i) − m x(i) values. The regression line in the slope–intercept form, y = m x + b , is then plotted along with the calculated prediction interval (estimated by means of the root-mean-square error).
I have added two options for how to handle pairs of points:
Method == "All" to use the slopes of all pairs of points;
Method == "Random" to use the slopes of randomly generated pairs of points.
The random choice of the pairs of points is based on the Wichmann–Hill is a pseudorandom number generator.
The reason for introducing the "Random" method is that the calculation of the median involves sorting the array of slopes (the size of N*(N-1)/2, where N is the number of sample points). This is a computationally demanding procedure, which runs into the limit on the cycle computation time (200 ms) set in TradingView. Therefore, the "All" method works only with Length < 50.
Also note that the number of lookback points is limited by by the maximum array size allowed in TradingView.
Literature
1. Sen, P. K. (1968) "Estimates of the regression coefficient based on Kendall's tau." JASA, 1379-1389.
2. Theil, H. (1950) "A rank-invariant method of linear and polynomial regression analysis." Reprinted in 1992 in Henri Theil’s contributions to economics and econometrics, Springer, 345-381.
3. en.wikipedia.org


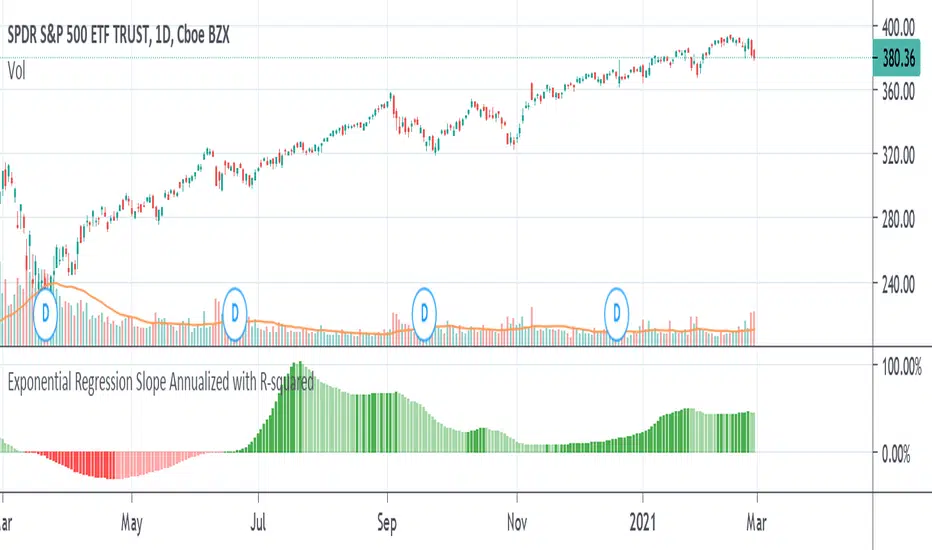
Exponential Regression Slope Annualized with R-squared HistogramMy other indicator shows the linear regression slope of the source. This one finds the exponential regression slope and optionally multiplies it by R-squared and optionally annualizes it. Multiplying by R-squared makes sure that the price movement was significant in order to avoid volatile movements that can throw off the slope value. Annualizing the exponential slope will let you see how much percentage you will make in a year if the price continues at its current pace.
The annualized number is the number of trading days in a year. This and the length might need adjusting for the extra bars that might be in futures or other markets. The number does not have to be a year. For example, it can be a month if you set the number to 20 or so trading days to find how much you would make in a month if price continues at its current pace, etc. This can also be used as an alternative to relative strength or rate of change.
Moving RegressionMoving Regression is a generalization of moving average and polynomial regression.
The procedure approximates a specified number of prior data points with a polynomial function of a user-defined degree. Then, polynomial interpolation of the last data point is used to construct a Moving Regression time series.
Application:
Moving Regression allows one to smooth noise on the analyzed chart, assess momentum, confirm trends, and establish areas of support and resistance.
In addition, it can be used as a simple stand-alone forecasting method to identify trend direction and trend reversal points. When the local polynomial is predicted to move up in the next time step, the color of the Moving Regression curve will be green. Otherwise, the color of the curve is red. This function is (de)activated using the Predict Trend Direction flag.
Selecting the model parameters:
The effects of the moving window Length and the Local Polynomial Degree are confounded. This allows for finding the optimal trade-off between noise (variance) and lag (bias). Higher Length and lower Polynomial Degree (such as 1, i.e. linear), will result in "smoother" time series but at the cost of greater lag. Increasing the Polynomial Degree to, for example, 2 (squared) while maintaining the Length will diminish the lag and thus compromise the noise-lag tradeoff.
Relation to other methods:
When the degree of the local polynomial is set to 0 (i.e., fitting data to a constant level), the Moving Regression time series exactly matches the Simple Moving Average of the same length.
