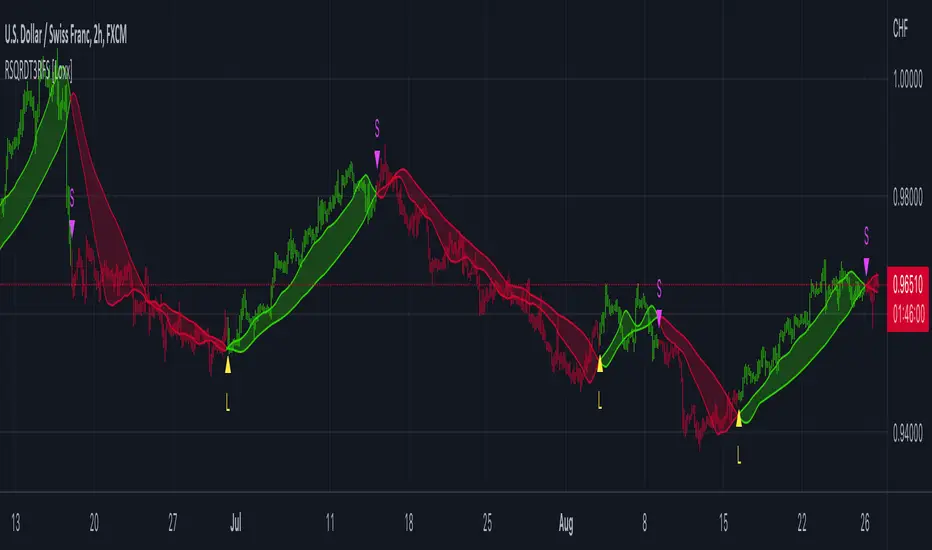
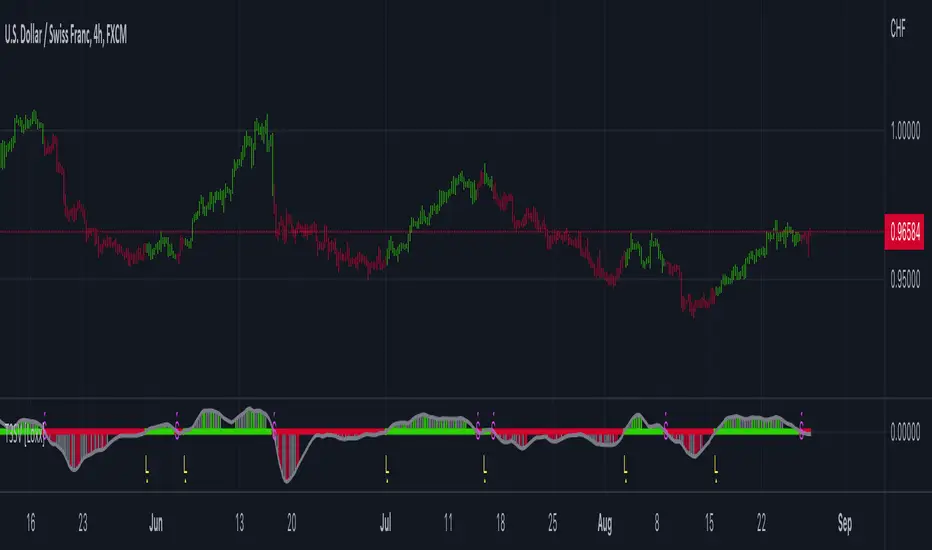
T3 ATR [DCAUT]█ T3 ATR
📊 ORIGINALITY & INNOVATION
The T3 ATR indicator represents an important enhancement to the traditional Average True Range (ATR) indicator by incorporating the T3 (Tilson Triple Exponential Moving Average) smoothing algorithm. While standard ATR uses fixed RMA (Running Moving Average) smoothing, T3 ATR introduces a configurable volume factor parameter that allows traders to adjust the smoothing characteristics from highly responsive to heavily smoothed output.
This innovation addresses a fundamental limitation of traditional ATR: the inability to adapt smoothing behavior without changing the calculation period. With T3 ATR, traders can maintain a consistent ATR period while adjusting the responsiveness through the volume factor, making the indicator adaptable to different trading styles, market conditions, and timeframes through a single unified implementation.
The T3 algorithm's triple exponential smoothing with volume factor control provides improved signal quality by reducing noise while maintaining better responsiveness compared to traditional smoothing methods. This makes T3 ATR particularly valuable for traders who need to adapt their volatility measurement approach to varying market conditions without switching between multiple indicator configurations.
📐 MATHEMATICAL FOUNDATION
The T3 ATR calculation process involves two distinct stages:
Stage 1: True Range Calculation
The True Range (TR) is calculated using the standard formula:
TR = max(high - low, |high - close |, |low - close |)
This captures the greatest of the current bar's range, the gap from the previous close to the current high, or the gap from the previous close to the current low, providing a comprehensive measure of price movement that accounts for gaps and limit moves.
Stage 2: T3 Smoothing Application
The True Range values are then smoothed using the T3 algorithm, which applies six exponential moving averages in succession:
First Layer: e1 = EMA(TR, period), e2 = EMA(e1, period)
Second Layer: e3 = EMA(e2, period), e4 = EMA(e3, period)
Third Layer: e5 = EMA(e4, period), e6 = EMA(e5, period)
Final Calculation: T3 = c1×e6 + c2×e5 + c3×e4 + c4×e3
The coefficients (c1, c2, c3, c4) are derived from the volume factor (VF) parameter:
a = VF / 2
c1 = -a³
c2 = 3a² + 3a³
c3 = -6a² - 3a - 3a³
c4 = 1 + 3a + a³ + 3a²
The volume factor parameter (0.0 to 1.0) controls the weighting of these coefficients, directly affecting the balance between responsiveness and smoothness:
Lower VF values (approaching 0.0): Coefficients favor recent data, resulting in faster response to volatility changes with minimal lag but potentially more noise
Higher VF values (approaching 1.0): Coefficients distribute weight more evenly across the smoothing layers, producing smoother output with reduced noise but slightly increased lag
📊 COMPREHENSIVE SIGNAL ANALYSIS
Volatility Level Interpretation:
High Absolute Values: Indicate strong price movements and elevated market activity, suggesting larger position risks and wider stop-loss requirements, often associated with trending markets or significant news events
Low Absolute Values: Indicate subdued price movements and quiet market conditions, suggesting smaller position risks and tighter stop-loss opportunities, often associated with consolidation phases or low-volume periods
Rapid Increases: Sharp spikes in T3 ATR often signal the beginning of significant price moves or market regime changes, providing early warning of increased trading risk
Sustained High Levels: Extended periods of elevated T3 ATR indicate sustained trending conditions with persistent volatility, suitable for trend-following strategies
Sustained Low Levels: Extended periods of low T3 ATR indicate range-bound conditions with suppressed volatility, suitable for mean-reversion strategies
Volume Factor Impact on Signals:
Low VF Settings (0.0-0.3): Produce responsive signals that quickly capture volatility changes, suitable for short-term trading but may generate more frequent color changes during minor fluctuations
Medium VF Settings (0.4-0.7): Provide balanced signal quality with moderate responsiveness, filtering out minor noise while capturing significant volatility changes, suitable for swing trading
High VF Settings (0.8-1.0): Generate smooth, stable signals that filter out most noise and focus on major volatility trends, suitable for position trading and long-term analysis
🎯 STRATEGIC APPLICATIONS
Position Sizing Strategy:
Determine your risk per trade (e.g., 1% of account capital - adjust based on your risk tolerance and experience)
Decide your stop-loss distance multiplier (e.g., 2.0x T3 ATR - this varies by market and strategy, test different values)
Calculate stop-loss distance: Stop Distance = Multiplier × Current T3 ATR
Calculate position size: Position Size = (Account × Risk %) / Stop Distance
Example: $10,000 account, 1% risk, T3 ATR = 50 points, 2x multiplier → Position Size = ($10,000 × 0.01) / (2 × 50) = $100 / 100 points = 1 unit per point
Important: The ATR multiplier (1.5x - 3.0x) should be determined through backtesting for your specific instrument and strategy - using inappropriate multipliers may result in stops that are too tight (frequent stop-outs) or too wide (excessive losses)
Adjust the volume factor to match your trading style: lower VF for responsive stop distances in short-term trading, higher VF for stable stop distances in position trading
Dynamic Stop-Loss Placement:
Determine your risk tolerance multiplier (typically 1.5x to 3.0x T3 ATR)
For long positions: Set stop-loss at entry price minus (multiplier × current T3 ATR value)
For short positions: Set stop-loss at entry price plus (multiplier × current T3 ATR value)
Trail stop-losses by recalculating based on current T3 ATR as the trade progresses
Adjust the volume factor based on desired stop-loss stability: higher VF for less frequent adjustments, lower VF for more adaptive stops
Market Regime Identification:
Calculate a reference volatility level using a longer-period moving average of T3 ATR (e.g., 50-period SMA)
High Volatility Regime: Current T3 ATR significantly above reference (e.g., 120%+) - favor trend-following strategies, breakout trades, and wider targets
Normal Volatility Regime: Current T3 ATR near reference (e.g., 80-120%) - employ standard trading strategies appropriate for prevailing market structure
Low Volatility Regime: Current T3 ATR significantly below reference (e.g., <80%) - favor mean-reversion strategies, range trading, and prepare for potential volatility expansion
Monitor T3 ATR trend direction and compare current values to recent history to identify regime transitions early
Risk Management Implementation:
Establish your maximum portfolio heat (total risk across all positions, typically 2-6% of capital)
For each position: Calculate position size using the formula Position Size = (Account × Individual Risk %) / (ATR Multiplier × Current T3 ATR)
When T3 ATR increases: Position sizes automatically decrease (same risk %, larger stop distance = smaller position)
When T3 ATR decreases: Position sizes automatically increase (same risk %, smaller stop distance = larger position)
This approach maintains constant dollar risk per trade regardless of market volatility changes
Use consistent volume factor settings across all positions to ensure uniform risk measurement
📋 DETAILED PARAMETER CONFIGURATION
ATR Length Parameter:
Default Setting: 14 periods
This is the standard ATR calculation period established by Welles Wilder, providing balanced volatility measurement that captures both short-term fluctuations and medium-term trends across most markets and timeframes
Selection Principles:
Shorter periods increase sensitivity to recent volatility changes and respond faster to market shifts, but may produce less stable readings
Longer periods emphasize sustained volatility trends and filter out short-term noise, but respond more slowly to genuine regime changes
The optimal period depends on your holding time, trading frequency, and the typical volatility cycle of your instrument
Consider the timeframe you trade: Intraday traders typically use shorter periods, swing traders use intermediate periods, position traders use longer periods
Practical Approach:
Start with the default 14 periods and observe how well it captures volatility patterns relevant to your trading decisions
If ATR seems too reactive to minor price movements: Increase the period until volatility readings better reflect meaningful market changes
If ATR lags behind obvious volatility shifts that affect your trades: Decrease the period for faster response
Match the period roughly to your typical holding time - if you hold positions for N bars, consider ATR periods in a similar range
Test different periods using historical data for your specific instrument and strategy before committing to live trading
T3 Volume Factor Parameter:
Default Setting: 0.7
This setting provides a reasonable balance between responsiveness and smoothness for most market conditions and trading styles
Understanding the Volume Factor:
Lower values (closer to 0.0) reduce smoothing, allowing T3 ATR to respond more quickly to volatility changes but with less noise filtering
Higher values (closer to 1.0) increase smoothing, producing more stable readings that focus on sustained volatility trends but respond more slowly
The trade-off is between immediacy and stability - there is no universally optimal setting
Selection Principles:
Match to your decision speed: If you need to react quickly to volatility changes for entries/exits, use lower VF; if you're making longer-term risk assessments, use higher VF
Match to market character: Noisier, choppier markets may benefit from higher VF for clearer signals; cleaner trending markets may work well with lower VF for faster response
Match to your preference: Some traders prefer responsive indicators even with occasional false signals, others prefer stable indicators even with some delay
Practical Adjustment Guidelines:
Start with default 0.7 and observe how T3 ATR behavior aligns with your trading needs over multiple sessions
If readings seem too unstable or noisy for your decisions: Try increasing VF toward 0.9-1.0 for heavier smoothing
If the indicator lags too much behind volatility changes you care about: Try decreasing VF toward 0.3-0.5 for faster response
Make meaningful adjustments (0.2-0.3 changes) rather than small increments - subtle differences are often imperceptible in practice
Test adjustments in simulation or paper trading before applying to live positions
📈 PERFORMANCE ANALYSIS & COMPETITIVE ADVANTAGES
Responsiveness Characteristics:
The T3 smoothing algorithm provides improved responsiveness compared to traditional RMA smoothing used in standard ATR. The triple exponential design with volume factor control allows the indicator to respond more quickly to genuine volatility changes while maintaining the ability to filter noise through appropriate VF settings. This results in earlier detection of volatility regime changes compared to standard ATR, particularly valuable for risk management and position sizing adjustments.
Signal Stability:
Unlike simple smoothing methods that may produce erratic signals during transitional periods, T3 ATR's multi-layer exponential smoothing provides more stable signal progression. The volume factor parameter allows traders to tune signal stability to their preference, with higher VF settings producing remarkably smooth volatility profiles that help avoid overreaction to temporary market fluctuations.
Comparison with Standard ATR:
Adaptability: T3 ATR allows adjustment of smoothing characteristics through the volume factor without changing the ATR period, whereas standard ATR requires changing the period length to alter responsiveness, potentially affecting the fundamental volatility measurement
Lag Reduction: At lower volume factor settings, T3 ATR responds more quickly to volatility changes than standard ATR with equivalent periods, providing earlier signals for risk management adjustments
Noise Filtering: At higher volume factor settings, T3 ATR provides superior noise filtering compared to standard ATR, producing cleaner signals for long-term analysis without sacrificing volatility measurement accuracy
Flexibility: A single T3 ATR configuration can serve multiple trading styles by adjusting only the volume factor, while standard ATR typically requires multiple instances with different periods for different trading applications
Suitable Use Cases:
T3 ATR is well-suited for the following scenarios:
Dynamic Risk Management: When position sizing and stop-loss placement need to adapt quickly to changing volatility conditions
Multi-Style Trading: When a single volatility indicator must serve different trading approaches (day trading, swing trading, position trading)
Volatile Markets: When standard ATR produces too many false volatility signals during choppy conditions
Systematic Trading: When algorithmic systems require a single, configurable volatility input that can be optimized for different instruments
Market Regime Analysis: When clear identification of volatility expansion and contraction phases is critical for strategy selection
Known Limitations:
Like all technical indicators, T3 ATR has limitations that users should understand:
Historical Nature: T3 ATR is calculated from historical price data and cannot predict future volatility with certainty
Smoothing Trade-offs: The volume factor setting involves a trade-off between responsiveness and smoothness - no single setting is optimal for all market conditions
Extreme Events: During unprecedented market events or gaps, T3 ATR may not immediately reflect the full scope of volatility until sufficient data is processed
Relative Measurement: T3 ATR values are most meaningful in relative context (compared to recent history) rather than as absolute thresholds
Market Context Required: T3 ATR measures volatility magnitude but does not indicate price direction or trend quality - it should be used in conjunction with directional analysis
Performance Expectations:
T3 ATR is designed to help traders measure and adapt to changing market volatility conditions. When properly configured and applied:
It can help reduce position risk during volatile periods through appropriate position sizing
It can help identify optimal times for more aggressive position sizing during stable periods
It can improve stop-loss placement by adapting to current market conditions
It can assist in strategy selection by identifying volatility regimes
However, volatility measurement alone does not guarantee profitable trading. T3 ATR should be integrated into a comprehensive trading approach that includes directional analysis, proper risk management, and sound trading psychology.
USAGE NOTES
This indicator is designed for technical analysis and educational purposes. T3 ATR provides adaptive volatility measurement but has limitations and should not be used as the sole basis for trading decisions. The indicator measures historical volatility patterns, and past volatility characteristics do not guarantee future volatility behavior. Market conditions can change rapidly, and extreme events may produce volatility readings that fall outside historical norms.
Traders should combine T3 ATR with directional analysis tools, support/resistance analysis, and other technical indicators to form a complete trading strategy. Proper backtesting and forward testing with appropriate risk management is essential before applying T3 ATR-based strategies to live trading. The volume factor parameter should be optimized for specific instruments and trading styles through careful testing rather than assuming default settings are optimal for all applications.
Indicador Pine Script®