Quantile-Based Adaptive Detection🙏🏻 Dedicated to John Tukey. He invented the boxplot, and I finalized it.
QBAD (Quantile-Based Adaptive Detection) is ‘the’ adaptive (also optionally weighted = ready for timeseries) boxplot with more senseful fences. Instead of hardcoded multipliers for outer fences, I base em on a set of quantile-based asymmetry metrics (you can view it as an ‘algorithmic’ counter part of central & standardized moments). So outer bands are Not hardcoded, not optimized, not cross-validated etc, simply calculated at O(nlogn).
You can use it literally everywhere in any context with any continuous data, in any task that requires statistical control, novelty || outlier detection, without worrying and doubting the sense in arbitrary chosen thresholds. Obviously, given the robust nature of quantiles, it would fit best the cases where data has problems.
The thresholds are:
Basis: the model of the data (median in our case);
Deviations: represent typical spread around basis, together form “value” in general sense;
Extensions: estimate data’s extremums via combination of quantile-based asymmetry metrics without relying on actual blunt min and max, together form “range” / ”frame”. Datapoints outside the frame/range are novelties or outliers;
Limits: based also on quantile asymmetry metrics, estimate the bounds within which values can ‘ever’ emerge given the current data generating process stays the same, together form “field”. Datapoints outside the field are very rare, happen when a significant change/structural break happens in current data-generating process, or when a corrupt datapoint emerges.
…
The first part of the post is for locals xd, the second is for the wanderers/wizards/creators/:
First part:
In terms of markets, mostly u gotta worry about dem instruments that represent crypto & FX assets: it’s either activity hence data sources there are decentralized, or data is fishy.
For a higher algocomplexity cost O(nlong), unlike MBAD that is 0(n), this thing (a control system in fact) works better with ishy data (contaminated with wrong values, incomplete, missing values etc). Read about the “ breakdown point of an estimator ” if you wanna understand it.
Even with good data, in cases when you have multiple instruments that represent the same asset, e.g. CL and BRN futures, and for some reason you wanna skip constructing a proper index of em (while you should), QBAD should be better put on each instrument individually.
Another reason to use this algo-based rather than math-based tool, might be in cases when data quality is all good, but the actual causal processes that generate the data are a bit inconsistent and/or possess ‘increased’ activity in a way. SO in high volatility periods, this tool should provide better.
In terms of built-ins you got 2 weightings: by sequence and by inferred volume delta. The former should be ‘On’ all the time when you work with timeseries, unless for a reason you want to consciously turn it off for a reason. The latter, you gotta keep it ‘On’ unless you apply the tool on another dataset that ain’t got that particular additional dimension.
Ain’t matter the way you gonna use it, moving windows, cumulative windows with or without anchors, that’s your freedom of will, but some stuff stays the same:
Basis and deviations are “value” levels. From process control perspective, if you pls, it makes sense to Not only fade or push based on these levels, but to also do nothing when things are ambiguous and/or don’t require your intervention
Extensions and limits are extreme levels. Here you either push or fade, doing nothing is not an option, these are decisive points in all the meanings
Another important thing, lately I started to see one kind of trend here on tradingview as well and in general in near quant sources, of applying averages, percentiles etc ‘on’ other stationary metrics, so called “indicators”. And I mean not for diagnostic or development reasons, for decision making xd
This is not the evil crime ofc, but hillbilly af, cuz the metrics are stationary it means that you can model em, fit a distribution, like do smth sharper. Worst case you have Bayesian statistics armed with high density intervals and equal tail intervals, and even some others. All this stuff is not hard to do, if u aint’t doing it, it’s on you.
So what I’m saying is it makes sense to apply QBAD on returns ‘of your strategy’, on volume delta, but Not on other metrics that already do calculations over their own moving windows.
...
Second part:
Looks like some finna start to have lil suspicions, that ‘maybe’ after all math entities in reality are more like blueprints, while actual representations are physical/mechanical/algorithmic. Std & centralized moments is a math entity that represents location, scale & asymmetry info, and we can use it no problem, when things are legit and consistent especially. Real world stuff tho sometimes deviates from that ideal, so we need smth more handy and real. Add to the mix the algo counter part of means: quantiles.
Unlike the legacy quantile-based asymmetry metrics from the previous century (check quantile skewness & kurtosis), I don’t use arbitrary sets of quantiles, instead we get a binary pattern that is totally geometric & natural (check the code if interested, I made it very damn explicit). In spirit with math based central & standardized moments, each consequent pair is wider empathizing tail info more and more for each higher order metric.
Unlike the classic box plot, where inner thresholds are quartiles and the rest are based on em, here the basis is median (minimises L1), I base inner thresholds on it, and we continue the pattern by basing the further set of levels on the previous set. So unlike the classic box plot, here we have coherency in construction, symmetry.
Another thing to pay attention to, tho for some reason ain’t many talk about it, it’s not conceptually right to think that “you got data and you apply std moments on it”. No, you apply it to ‘centered around smth’ data. That ‘smth’ should minimize L2 error in case of math, L1 error in case of algo, and L0 error in case of learning/MLish/optimizational/whatever-you-cal-it stuff. So in the case of L0, that’s actually the ‘mode’ of KDE, but that’s for another time. Anyways, in case of L2 it’s mean, so we center data around mean, and apply std moments on residuals. That’s the precise way of framing it. If you understand this, suddenly very interesting details like 0th and 1st central moments start to make sense. In case of quantiles, we center data around the median, and do further processing on residuals, same.
Oth moment (I call it init) is always 1, tho it’s interesting to extrapolate backwards the sequence for higher order moments construction, to understand how we actually end up with this zero.
1st moment (I call it bias) of residuals would be zero if you match centering and residuals analysis methods. But for some reason you didn’t do that (e.g centered data around midhinge or mean and applied QBAD on the centered data), you have to account for that bias.
Realizing stuff > understanding stuff
Learning 2981234 human invented fields < realizing the same unified principles how the Universe works
∞
Quantile
Quantile Regression Bands [BackQuant]Quantile Regression Bands
Tail-aware trend channeling built from quantiles of real errors, not just standard deviations.
What it does
This indicator fits a simple linear trend over a rolling lookback and then measures how price has actually deviated from that trend during the window. It then places two pairs of bands at user-chosen quantiles of those deviations (inner and outer). Because bands are based on empirical quantiles rather than a symmetric standard deviation, they adapt to skewed and fat-tailed behaviour and often hug price better in trending or asymmetric markets.
Why “quantile” bands instead of Bollinger-style bands?
Bollinger Bands assume a (roughly) symmetric spread around the mean; quantiles don’t—upper and lower bands can sit at different distances if the error distribution is skewed.
Quantiles are robust to outliers; a single shock won’t inflate the bands for many bars.
You can choose tails precisely (e.g., 1%/99% or 5%/95%) to match your risk appetite.
How it works (intuitive)
Center line — a rolling linear regression approximates the local trend.
Residuals — for each bar in the lookback, the indicator looks at the gap between actual price and where the line “expected” price to be.
Quantiles — those gaps are sorted; you select which percentiles become your inner/outer offsets.
Bands — the chosen quantile offsets are added to the current end of the regression line to draw parallel support/resistance rails.
Smoothing — a light EMA can be applied to reduce jitter in the line and bands.
What you see
Center (linear regression) line (optional).
Inner quantile bands (e.g., 25th/75th) with optional translucent fill.
Outer quantile bands (e.g., 1st/99th) with a multi-step gradient to visualise “tail zones.”
Optional bar coloring: bars trend-colored by whether price is rising above or falling below the center line.
Alerts when price crosses the outer bands (upper or lower).
How to read it
Trend & drift — the slope of the center line is your local trend. Persistent closes on the same side of the center line indicate directional drift.
Pullbacks — tags of the inner band often mark routine pullbacks within trend. Reaction back to the center line can be used for continuation entries/partials.
Tails & squeezes — outer-band touches highlight statistically rare excursions for the chosen window. Frequent outer-band activity can signal regime change or volatility expansion.
Asymmetry — if the upper band sits much further from the center than the lower (or vice versa), recent behaviour has been skewed. Trade management can be adjusted accordingly (e.g., wider take-profit upslope than downslope).
A simple trend interpretation can be derived from the bar colouring
Good use-cases
Volatility-aware mean reversion — fade moves into outer bands back toward the center when trend is flat.
Trend participation — buy pullbacks to the inner band above a rising center; flip logic for shorts below a falling center.
Risk framing — set dynamic stops/targets at quantile rails so position sizing respects recent tail behaviour rather than fixed ticks.
Inputs (quick guide)
Source — price input used for the fit (default: close).
Lookback Length — bars in the regression window and residual sample. Longer = smoother, slower bands; shorter = tighter, more reactive.
Inner/Outer Quantiles (τ) — choose your “typical” vs “tail” levels (e.g., 0.25/0.75 inner, 0.01/0.99 outer).
Show toggles — independently toggle center line, inner bands, outer bands, and their fills.
Colors & transparency — customize band and fill appearance; gradient shading highlights the tail zone.
Band Smoothing Length — small EMA on lines to reduce stair-step artefacts without meaningfully changing levels.
Bar Coloring — optional trend tint from the center line’s momentum.
Practical settings
Swing trading — Length 75–150; inner τ = 0.25/0.75, outer τ = 0.05/0.95.
Intraday — Length 50–100 for liquid futures/FX; consider 0.20/0.80 inner and 0.02/0.98 outer in high-vol assets.
Crypto — Because of fat tails, try slightly wider outers (0.01/0.99) and keep smoothing at 2–4 to tame weekend jumps.
Signal ideas
Continuation — in an uptrend, look for pullback into the lower inner band with a close back above the center as a timing cue.
Exhaustion probe — in ranges, first touch of an outer band followed by a rejection candle back inside the inner band often precedes mean-reversion swings.
Regime shift — repeated closes beyond an outer band or a sharp re-tilt in the center line can mark a new trend phase; adjust tactics (stop-following along the opposite inner band).
Alerts included
“Price Crosses Upper Outer Band” — potential overextension or breakout risk.
“Price Crosses Lower Outer Band” — potential capitulation or breakdown risk.
Notes
The fit and quantiles are computed on a fixed rolling window and do not repaint; bands update as the window moves forward.
Quantiles are based on the recent distribution; if conditions change abruptly, expect band widths and skew to adapt over the next few bars.
Parameter choices directly shape behaviour: longer windows favour stability, tighter inner quantiles increase touch frequency, and extreme outer quantiles highlight only the rarest moves.
Final thought
Quantile bands answer a simple question: “How unusual is this move given the current trend and the way price has been missing it lately?” By scoring that question with real, distribution-aware limits rather than one-size-fits-all volatility you get cleaner pullback zones in trends, more honest “extreme” tags in ranges, and a framework for risk that matches the market’s recent personality.

Rolling QuartilesThis script will continuously draw a boxplot to represent quartiles associated with data points in the current rolling window.
Description :
A quartile is a statistical term that refers to the division of a dataset based on percentiles.
Q1 : Quartile 1 - 25th percentile
Q2 : Quartile 2 - 50th percentile, as known as the median
Q3 : Quartile 3 - 75th percentile
Other points to note:
Q0: the minimum
Q4: the maximum
Other properties :
- Q1 to Q3: a range is known as the interquartile range ( IQR ). It describes where 50% of data approximately lie.
- Line segments connecting IQR to min and max (Q0→Q1, and Q3→Q4) are known as whiskers . Data lying outside the whiskers are considered as outliers. However, such extreme values will not be found in a rolling window because whenever new datapoints are introduced to the dataset, the oldest values will get dropped out, leaving Q0 and Q4 to always point to the observable min and max values.
Applications :
This script has a feature that allows moving percentiles (moving values of Q1, Q2, and Q3) to be shown. This can be applied for trading in ways such as:
- Q2: as alternative to a SMA that uses the same lookback period. We know that the Mean (SMA) is highly sensitive to extreme values. On the other hand, Median (Q2) is less affected by skewness. Putting it together, if the SMA is significantly lower than Q2, then price is regarded as negatively skewed; prices of a few candles are likely exceptionally lower. Vice versa when price is positively skewed.
- Q1 and Q3: as lower and upper bands. As mentioned above, the IQR covers approximately 50% of data within the rolling window. If price is normally distributed, then Q1 and Q3 bands will overlap a bollinger band configured with +/- 0.67x standard deviations (modifying default: 2) above and below the mean.
- The boxplot, combined with TradingView's builtin bar replay feature, makes a great tool for studies purposes. This helps visualization of price at a chosen instance of time. Speaking of which, it can also be used in conjunction with a fixed volume profile to compare and contrast the effects (in terms of price range) with and without consideration of weights by volume.
Parameters :
- Lookback: The size of the rolling window.
- Offset: Location of boxplot, right hand side relative to recent bar.
- Source data: Data points for observation, default is closing price
- Other options such as color, and whether to show/hide various lines.
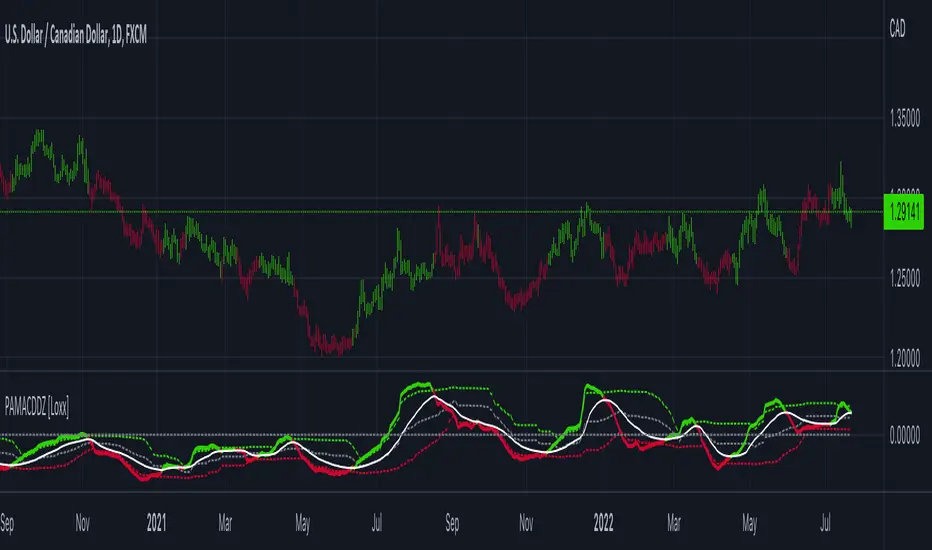
PA-Adaptive MACD w/ Variety Levels [Loxx]PA-Adaptive MACD w/ Variety Levels is a Phase Accumulation Adaptive MACD with both floating and quantile levels. This is tuned for Forex. You'll have to adjust the Phase Accumulation Cycle settings to work for crypto and stock markets.
What is MACD?
Moving average convergence divergence ( MACD ) is a trend-following momentum indicator that shows the relationship between two moving averages of a security’s price. The MACD is calculated by subtracting the 26-period exponential moving average ( EMA ) from the 12-period EMA .
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
Included:
Zero-line and signal cross options for bar coloring, signals, and alerts
Alerts
Signals
Loxx's Expanded Source Types
4 moving average types