RSI Profile [Kodexius]RSI Profile is an advanced technical indicator that turns the classic RSI into a distribution profile instead of a single oscillating line. Rather than only showing where the RSI is at the current bar, it displays where the RSI has spent most of its time or most of its volume over a user defined lookback period.
The script builds a histogram of RSI values between 0 and 100, splits that range into configurable bins, and then projects the result to the right side of the chart. This gives you a clear visual representation of the RSI structure, including the Point of Control (POC), the Value Area High (VAH), and the Value Area Low (VAL). The POC marks the RSI level with the highest activity, while VAH and VAL bracket the percentage based value area around it.
By combining standard RSI, a distribution profile, and value area logic, this tool lets you study RSI behavior statistically instead of only bar by bar. You can immediately see whether the current RSI reading is located inside the dominant zone, extended above it, or depressed below it, and whether the recent regime has been biased toward overbought, oversold, or neutral territory. This is particularly useful for swing traders, mean reversion systems, and anyone who wants to integrate RSI context into a more profile oriented workflow.
🔹 Features
1. RSI-Based Distribution Profile
-Builds a histogram of RSI values between 0 and 100.
-The RSI range is divided into a user-defined number of bins (e.g., 30 bins).
-Each bin represents a band of RSI values, such as 0–3.33, 3.33–6.66, ..., 96.66–100.
-For each bar in the lookback period, the script:
-Finds which bin the RSI value belongs to
Adds either:
-1.0 → if using time/frequency
-volume → if using volume-weighted RSI distribution
This creates a clear profile of where RSI has been concentrated over the chosen lookback window.
2. Time / Volume Weighting Mode
Under Profile Settings, you can choose:
-Weight by Volume = false
→ Profile is built using time spent at each RSI level (frequency).
-Weight by Volume = true
→ Profile is built using volume traded at each RSI level.
This flexibility allows you to decide whether you want:
-A pure momentum structure (time spent at each RSI)
-Or a participation-weighted structure (where higher-volume zones are emphasized)
3. Configurable Lookback & Resolution
-Profile Lookback: number of historical bars to analyze.
-Number of Bins: controls the resolution of the histogram:
Fewer bins → smoother, fewer gaps
More bins → more detail, but potentially more visual sparsity
-Profile Width (Bars): defines how wide the histogram extends into the future (visually), converted into time using average bar duration.
This provides a balance between performance, clarity, and visual density.
4. Value Area, POC, VAH, VAL
The script computes:
-POC (Point of Control)
→ The RSI bin with the highest total value (time or volume).
-Value Area (VA)
→ The range of RSI bins that contain a user-specified percentage of total activity (e.g., 70%).
-VAH & VAL
→ Upper and lower RSI boundaries of this Value Area.
These are then drawn as horizontal lines and labeled:
-POC line and label
-VAH line and label
-VAL line and label
This gives you a profile-style view similar to classical volume profile, but entirely on the RSI axis.
5. Color Coding & Visual Design
The histogram bars (boxes) are colored using a smart scheme:
-Below 30 RSI → Oversold zone, uses the Oversold Color (default: green).
-Above 70 RSI → Overbought zone, uses the Overbought Color (default: red).
-Between 30 and 70 RSI → Neutral zone, uses a gradient between:
A soft blue at lower mid levels
A soft orange at higher mid levels
Additional styling:
-POC bin is highlighted in bright yellow.
-Bins inside the Value Area → lower transparency (more solid).
-Bins outside the Value Area → higher transparency (faded).
This makes it easy to visually distinguish:
-Core RSI activity (VA)
-Extremes (oversold/overbought)
-The single dominant zone (POC)
🔹 Calculations
This section summarizes the core logic behind the script and highlights the main building blocks that power the profile.
1. Profile Structure and Bin Initialization
A custom Profile type groups together configuration, bins and drawing objects. During initialization, the script splits the 0 to 100 RSI range into evenly spaced bins, each represented by a Bin record:
method initBins(Profile p) =>
p.bins := array.new()
float step = 100.0 / p.binCount
for i = 0 to p.binCount - 1
float low = i * step
float high = (i + 1) * step
p.bins.push(Bin.new(low, high, 0.0, box(na)))
2. Filling the Profile Over the Lookback Window
On the last bar, the script clears previous drawings and walks backward through the selected lookback window. For each historical bar, it reads the RSI and volume series and feeds them into the profile:
if barstate.islast
myProfile.reset()
int start = math.max(0, bar_index - lookback)
int end = bar_index
for i = 0 to (end - start)
float r = rsi
float v = volume
if not na(r)
myProfile.add(r, v)
The add method converts each RSI value into a bin index and accumulates either a frequency count or the bar volume, depending on the chosen mode:
method add(Profile p, float rsiValue, float volumeValue) =>
int idx = int(rsiValue / (100.0 / p.binCount))
if idx >= p.binCount
idx := p.binCount - 1
if idx < 0
idx := 0
Bin targetBin = p.bins.get(idx)
float addedValue = p.useVolume ? volumeValue : 1.0
targetBin.value += addedValue
3. Finding POC and Building the Value Area
Inside the draw method, the script first scans all bins to determine the maximum value and the total sum. The bin with the highest value becomes the POC. The value area is then constructed by expanding from that center bin until the desired percentage of total activity is covered:
for in p.bins
totalVal += b.value
if b.value > maxVal
maxVal := b.value
pocIdx := i
float vaTarget = totalVal * (p.vaPercent / 100.0)
float currentVaVol = maxVal
int upIdx = pocIdx
int downIdx = pocIdx
while currentVaVol < vaTarget
float upVol = (upIdx < p.binCount - 1) ? p.bins.get(upIdx + 1).value : 0.0
float downVol = (downIdx > 0) ? p.bins.get(downIdx - 1).value : 0.0
if upVol == 0 and downVol == 0
break
if upVol >= downVol
upIdx += 1
currentVaVol += upVol
else
downIdx -= 1
currentVaVol += downVol
Normaldistribution

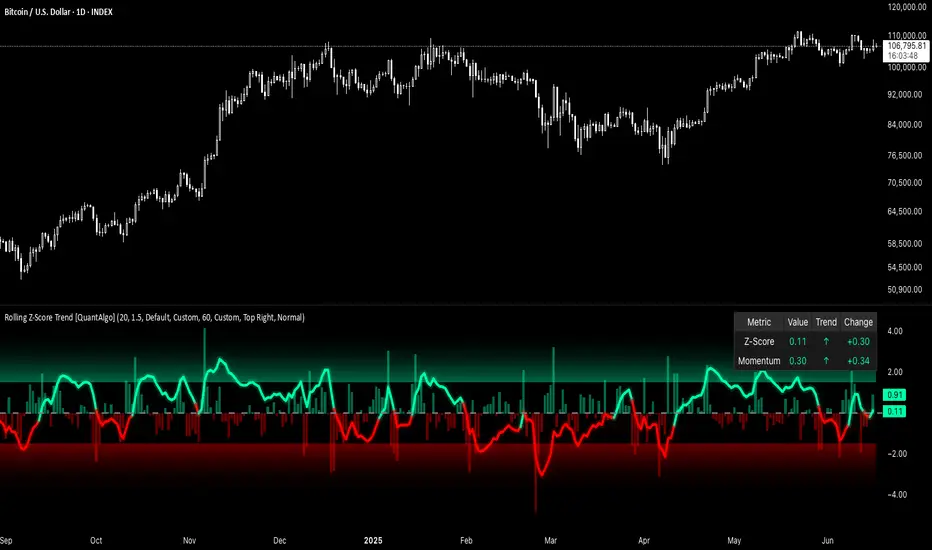
Rolling Z-Score Trend [QuantAlgo]🟢 Overview
The Rolling Z-Score Trend measures how far the current price deviates from its rolling mean in terms of standard deviations. It transforms price data into standardized scores to identify overbought and oversold conditions while tracking momentum shifts.
The indicator displays a Z-Score line showing price deviation from statistical norms, with background momentum columns showing the rate of change in these deviations. This helps traders and investors identify mean reversion opportunities and momentum shifts across different asset classes and timeframes.
🟢 How It Works
The indicator uses the Z-Score formula: Z = (X - μ) / σ, where X is the current closing price, μ is the rolling mean, and σ is the rolling standard deviation over a user-defined lookback period. This creates a dynamic baseline that adapts to changing market conditions and standardizes price movements for interpretation across different assets and volatility conditions. The raw Z-Score undergoes 3-period EMA smoothing to reduce noise while maintaining responsiveness to market signals.
Beyond the basic Z-Score calculation, the indicator measures the rate of change in Z-Score values between successive bars, displayed as background momentum columns. This momentum component shows acceleration and deceleration of statistical deviations. All calculations are processed through confirmation filters, displaying signals only on confirmed bars to reduce premature signals based on incomplete price action.
🟢 How to Use
1. Z-Score Interpretation and Threshold Zones
Positive Values (Above Zero) : Price trading above statistical mean, suggesting bullish momentum or potential overbought conditions
Negative Values (Below Zero) : Price trading below statistical mean, suggesting bearish momentum or potential oversold conditions
Zero Line Crosses : Signal transitions between statistical regimes and potential trend changes
Upper Threshold Zone : Area above entry threshold (default 1.5) indicating potential overbought conditions
Lower Threshold Zone : Area below negative entry threshold (default -1.5) indicating potential oversold conditions
Extreme Values (±2.0 or higher) : Statistically significant deviations that may indicate reversal opportunities
2. Momentum Background Analysis and Info Table
Green Columns : Accelerating positive momentum in Z-Score values
Red Columns : Accelerating negative momentum in Z-Score values
Column Height : Magnitude of momentum change between bars
Momentum Divergence : When columns contradict primary Z-Score direction, often signals impending reversals
Info Table : Displays real-time numerical values for both Z-Score and momentum, including trend direction indicators and bar-to-bar change calculations for position management
3. Preconfigured Settings
Default : Balanced performance across multiple timeframes and asset classes for general trading and medium-term position management.
Scalping : Responsive setup for ultra-short-term trading on 1-15 minute charts with frequent signals and increased sensitivity to quick price movements.
Swing Trading : Optimized for multi-day positions with noise filtering, focusing on larger price swings. Most effective on 1-4 hour and daily timeframes.
Trend Following : Maximum smoothing that prioritizes established trends over short-term volatility. Generates fewer signals for daily and weekly charts.
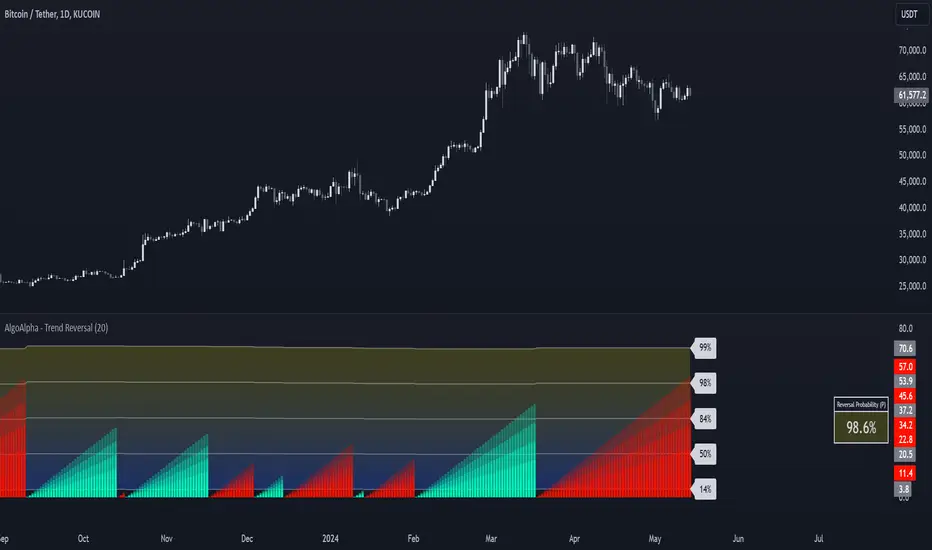
Trend Reversal Probability [Algoalpha]Introducing Trend Reversal Probability by AlgoAlpha – a powerful indicator that estimates the likelihood of trend reversals based on an advanced custom oscillator and duration-based statistics. Designed for traders who want to stay ahead of potential market shifts, this indicator provides actionable insights into trend momentum and reversal probabilities.
Key Features :
🔧 Custom Oscillator Calculation: Combines a dual SMA strategy with a proprietary RSI-like calculation to detect market direction and strength.
📊 Probability Levels & Visualization: Plots average signal durations and their statistical deviations (±1, ±2, ±3 SD) on the chart for clear visual guidance.
🎨 Dynamic Color Customization: Choose your preferred colors for upward and downward trends, ensuring a personalized chart view.
📈 Signal Duration Metrics: Tracks and displays signal durations with columns representing key percentages (80%, 60%, 40%, and 20%).
🔔 Alerts for High Probability Events: Set alerts for significant reversal probabilities (above 84% and 98% or below 14%) to capture key trading moments.
How to Use :
Add the Indicator: Add Trend Reversal Probability to your favorites by clicking the star icon.
Market Analysis: Use the plotted probability levels (average duration and ±SD bands) to identify overextended trends and potential reversals. Use the color of the duration counter to identify the current trend.
Leverage Alerts: Enable alerts to stay informed of high or extreme reversal probabilities without constant chart monitoring.
How It Works :
The indicator begins by calculating a custom oscillator using short and long simple moving averages (SMA) of the midpoint price. A proprietary RSI-like formula then transforms these values to estimate trend direction and momentum. The duration between trend reversals is tracked and averaged, with standard deviations plotted to provide probabilistic guidance on trend longevity. Additionally, the indicator incorporates a cumulative probability function to estimate the likelihood of a trend reversal, displaying the result in a data table for easy reference. When probability levels cross key thresholds, alerts are triggered, helping traders take timely action.
GaussianDistributionLibrary "GaussianDistribution"
This library defines a custom type `distr` representing a Gaussian (or other statistical) distribution.
It provides methods to calculate key statistical moments and scores, including mean, median, mode, standard deviation, variance, skewness, kurtosis, and Z-scores.
This library is useful for analyzing probability distributions in financial data.
Disclaimer:
I am not a mathematician, but I have implemented this library to the best of my understanding and capacity. Please be indulgent as I tried to translate statistical concepts into code as accurately as possible. Feedback, suggestions, and corrections are welcome to improve the reliability and robustness of this library.
mean(source, length)
Calculate the mean (average) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Mean (μ)
stdev(source, length)
Calculate the standard deviation (σ) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
Returns: Standard deviation (σ)
skewness(source, length, mean, stdev)
Calculate the skewness (γ₁) of the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Skewness (γ₁)
skewness(source, length)
Overloaded skewness to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Skewness (γ₁)
mode(mean, stdev, skewness)
Estimate mode - Most frequent value in the distribution (approximation based on skewness)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Mode
mode(source, length)
Overloaded mode to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Mode
median(mean, stdev, skewness)
Estimate median - Middle value of the distribution (approximation)
Parameters:
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
@return Median
median(source, length)
Overloaded median to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Median
variance(stdev)
Calculate variance (σ²) - Square of the standard deviation
Parameters:
stdev (float) : the standard deviation (σ) of the distribution
@return Variance (σ²)
variance(source, length)
Overloaded variance to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Variance (σ²)
kurtosis(source, length, mean, stdev)
Calculate kurtosis (γ₂) - Degree of "tailedness" in the distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Kurtosis (γ₂)
kurtosis(source, length)
Overloaded kurtosis to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Kurtosis (γ₂)
normal_score(source, mean, stdev)
Calculate Z-score (standard score) assuming a normal distribution
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
@return Z-Score
normal_score(source, length)
Overloaded normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
non_normal_score(source, mean, stdev, skewness, kurtosis)
Calculate adjusted Z-score considering skewness and kurtosis
Parameters:
source (float) : Distribution source (typically a price or indicator series)
mean (float) : the mean (average) of the distribution
stdev (float) : the standard deviation (σ) of the distribution
skewness (float) : the skewness (γ₁) of the distribution
kurtosis (float) : the "tailedness" in the distribution
@return Z-Score
non_normal_score(source, length)
Overloaded non_normal_score to calculate from source and length
Parameters:
source (float) : Distribution source (typically a price or indicator series)
length (int) : Window length for the distribution (must be >= 30 for meaningful statistics)
@return Z-Score
method init(this)
Initialize all statistical fields of the `distr` type
Namespace types: distr
Parameters:
this (distr)
method init(this, source, length)
Overloaded initializer to set source and length
Namespace types: distr
Parameters:
this (distr)
source (float)
length (int)
distr
Custom type to represent a Gaussian distribution
Fields:
source (series float) : Distribution source (typically a price or indicator series)
length (series int) : Window length for the distribution (must be >= 30 for meaningful statistics)
mode (series float) : Most frequent value in the distribution
median (series float) : Middle value separating the greater and lesser halves of the distribution
mean (series float) : μ (1st central moment) - Average of the distribution
stdev (series float) : σ or standard deviation (square root of the variance) - Measure of dispersion
variance (series float) : σ² (2nd central moment) - Squared standard deviation
skewness (series float) : γ₁ (3rd central moment) - Asymmetry of the distribution
kurtosis (series float) : γ₂ (4th central moment) - Degree of "tailedness" relative to a normal distribution
normal_score (series float) : Z-score assuming normal distribution
non_normal_score (series float) : Adjusted Z-score considering skewness and kurtosis
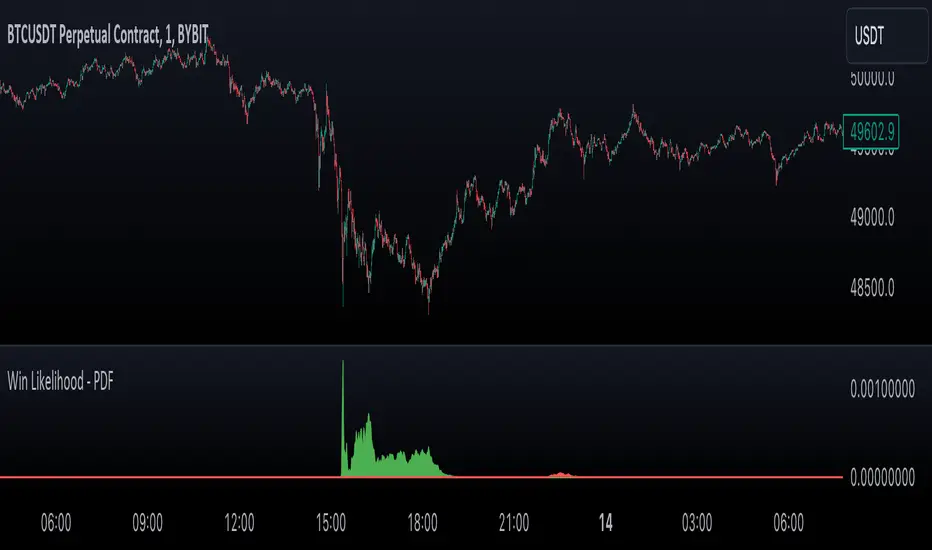
Likelihood of Winning - Probability Density FunctionIn developing the "Likelihood of Winning - Probability Density Function (PDF)" indicator, my aim was to offer traders a statistical tool to quantify the probability of reaching target prices. This indicator, grounded in risk assessment principles, enables users to analyze potential outcomes based on the normal distribution, providing insights into market dynamics.
The tool's flexibility allows for customization of the data series, lookback periods, and target settings for both long and short scenarios. It features a color-coded visualization to easily distinguish between probabilities of hitting specified targets, enhancing decision-making in trading strategies.
I'm excited to share this indicator with the trading community, hoping it will enhance data-driven decision-making and offer a deeper understanding of market risks and opportunities. My goal is to continuously improve this tool based on user feedback and market evolution, contributing to more informed trading practices.
This indicator leverages the "NormalDistributionFunctions" library, enabling easy integration into other indicators or strategies. Users can readily embed advanced statistical analysis into their trading tools, fostering innovation within the Pine Script community.
NormalDistributionFunctionsLibrary "NormalDistributionFunctions"
The NormalDistributionFunctions library encompasses a comprehensive suite of statistical tools for financial market analysis. It provides functions to calculate essential statistical measures such as mean, standard deviation, skewness, and kurtosis, alongside advanced functionalities for computing the probability density function (PDF), cumulative distribution function (CDF), Z-score, and confidence intervals. This library is designed to assist in the assessment of market volatility, distribution characteristics of asset returns, and risk management calculations, making it an invaluable resource for traders and financial analysts.
meanAndStdDev(source, length)
Calculates and returns the mean and standard deviation for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
length (int) : int: The lookback period for the calculation.
Returns: Returns an array where the first element is the mean and the second element is the standard deviation of the data series for the given period.
skewness(source, mean, stdDev, length)
Calculates and returns skewness for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns skewness value
kurtosis(source, mean, stdDev, length)
Calculates and returns kurtosis for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns kurtosis value
pdf(x, mean, stdDev)
pdf: Calculates the probability density function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the PDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the probability density function value for x.
cdf(x, mean, stdDev)
cdf: Calculates the cumulative distribution function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the CDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the cumulative distribution function value for x.
confidenceInterval(mean, stdDev, size, confidenceLevel)
Calculates the confidence interval for a data series mean.
Parameters:
mean (float) : float: The mean of the data series.
stdDev (float) : float: The standard deviation of the data series.
size (int) : int: The sample size.
confidenceLevel (float) : float: The confidence level (e.g., 0.95 for 95% confidence).
Returns: Returns the lower and upper bounds of the confidence interval.
MeanReversion - LogReturn/Vola ZScoreShows the z-Score of log-return (blue line) and volatility (black line). In statistics, the z-score is the number of standard deviations by which a value of a raw score is above or below the mean value.
This indicator aggregates z-score based on two indicators:
MeanReversion by Logarithmic Returns
MeanReversion by Volatility
Change the time period in bars for longer or shorter time frames. At a daily chart 252 mean on trading year, 21 mean one trading month.

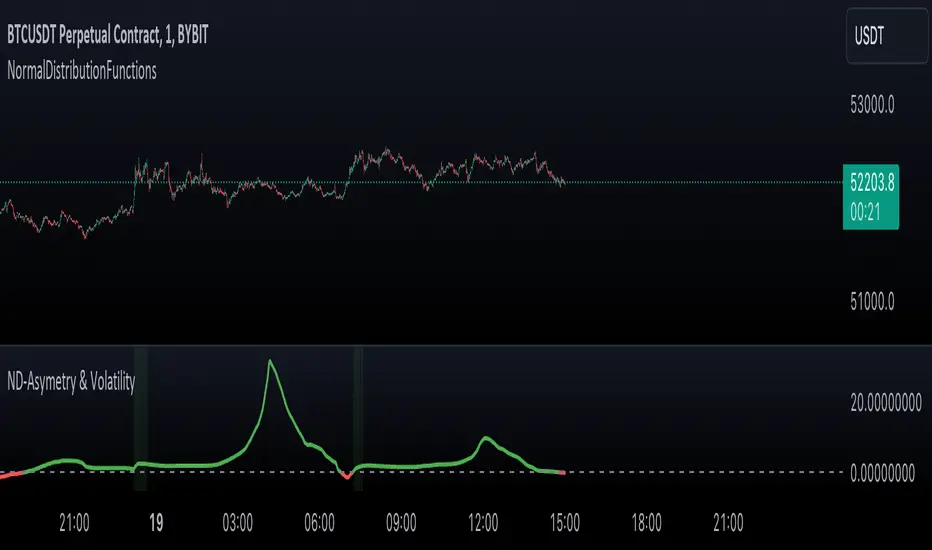
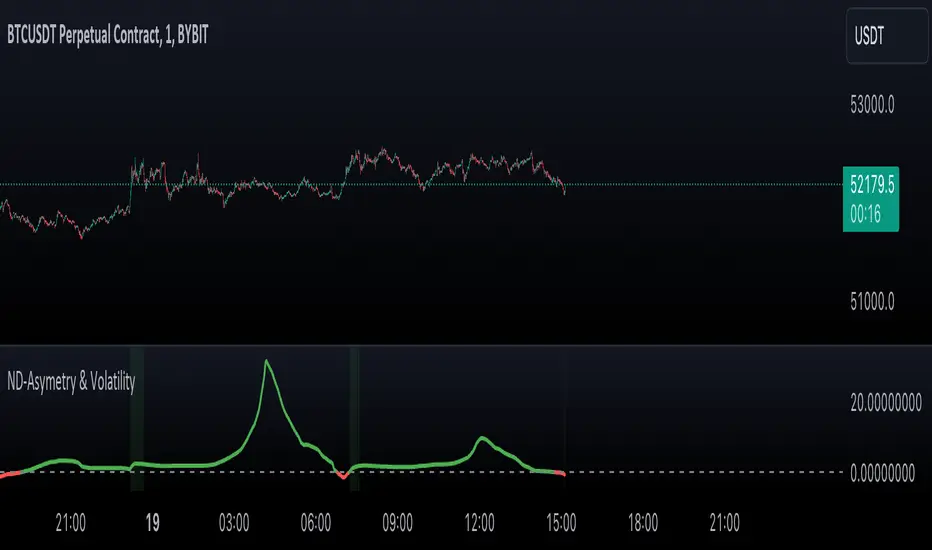
Normal Distribution Asymmetry & Volatility ZonesNormal Distribution Asymmetry & Volatility Zones Indicator provides insights into the skewness of a price distribution and identifies potential volatility zones in the market. The indicator calculates the skewness coefficient, indicating the asymmetry of the price distribution, and combines it with a measure of volatility to define buy and sell zones.
The key features of this indicator include :
Skewness Calculation : It calculates the skewness coefficient, a statistical measure that reveals whether the price distribution is skewed to the left (negative skewness) or right (positive skewness).
Volatility Zones : Based on the skewness and a user-defined volatility threshold, the indicator identifies buy and sell zones where potential price movements may occur. Buy zones are marked when skewness is negative and prices are below a volatility threshold. Sell zones are marked when skewness is positive and prices are above the threshold.
Signal Source Selection : Traders can select the source of price data for analysis, allowing flexibility in their trading strategy.
Customizable Parameters : Users can adjust the length of the distribution, the volatility threshold, and other parameters to tailor the indicator to their specific trading preferences and market conditions.
Visual Signals : Buy and sell zones are visually displayed on the chart, making it easy to identify potential trade opportunities.
Background Color : The indicator changes the background color of the chart to highlight significant zones, providing a clear visual cue for traders.
By combining skewness analysis and volatility thresholds, this indicator offers traders a unique perspective on potential market movements, helping them make informed trading decisions. Please note that trading involves risks, and this indicator should be used in conjunction with other analysis and risk management techniques.
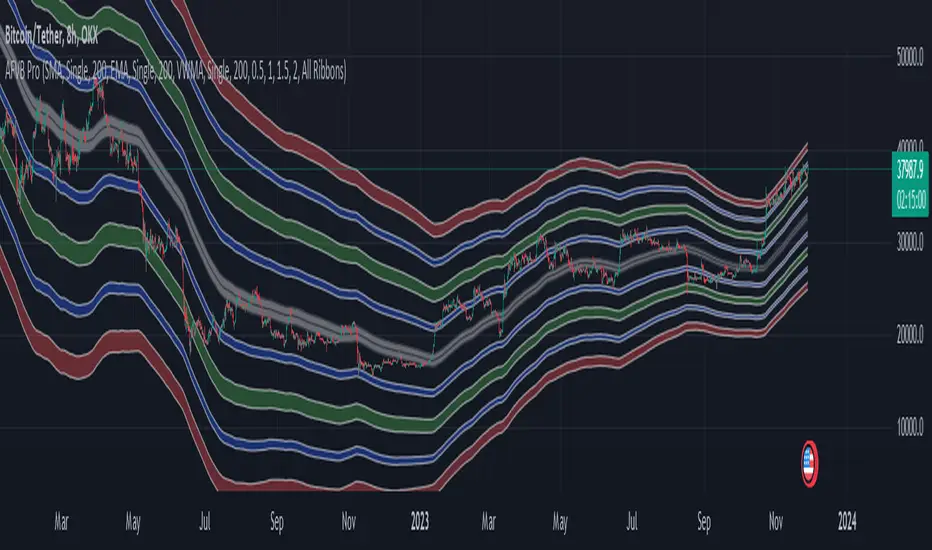
Apeiron Fair Value BandsThe Apeiron Fair Value Bands take into account a given MA and determine a Fair Value Area (FVA) for the price of a certain asset. The script plots a MA and a tolerance ribbon for it, as well as 2 bands (preset to 1 Standard deviations and 2 Standard deviations respectively, which can be manually changed) with a tolerance ribbon as well.
This creates 3 areas of interest:
The MA ribbon
The inside of the first upper and lower band (1 standard deviation) where price should stay within around 68% percent of the time according to the normal distribution
The inside of the second upper and lower band (2 standard deviations) where price should stay within around 95% percent of the time according to the normal distribution
Taking this into account, Fair Value analysis can be done:
Premium and Discount Prices: From a very simplistic point of view, when price is below a MA it can be considered to be at a discount and when it is above at a premium. Combining that idea with the levels given by the bands, we can determine if we are buying at premium or at a discount, specially on HTF and when considering investing, thus allowing to enter or exit the market with a higher probability of being on the right side of the trend and at a good level. As seen on the example, buying or selling at the highlighted levels would have been profitable with little drawdown.
VAH & VAL: (1 Standard Deviation Bands) Same as a Market Profile, price will stay in here "most" of the time. And particularly during ranging periods, they will provide potential revesal levels. As well, once prices breaks out of it, depending of the reaction to the second band, we can consider it a deviation or the beggining of a new trend. During strong trends, the bands can also serve as a correction support as the MA would do
New Fair Vaue Range: Once a new trend has begun, it will often slide on or break through Band 2, which can be interpreted as price creating a new Fair Value Range low or high. As seen on the chart, once price breaks out, those levels tend to be respected and relevant during corrections. I must make it very clear that this is just an analytical feature meant to be used in confluence with S/R, Supply & Demand, FVGs, Fibs or others. While it can be accurate sometimes, it might not be other times and be only "close".
Exhaustions: I call exhaustions to the scenarios when price keeps going up/down but it fails to keep pushing the fair value area with it. This indicates weakness in the trend and a potential reversal or correction. These appear on all Timeframes and symbols and are very good indications of tops and bottoms, specially after strong rallies or crashes. In the latter cases, waiting for price to re-enter it's FVA, provides great entries at the Bands levels.
Other features / Suggested Uses:
Middle levels: On the setup menu you can select different Standard deviation settings for each band including: 0.5, 1, 1.5, 2, 2.5 and 3. While the most relevant settings are 1 & 2, having their middle levels on the chart can provide extra levels for very tight ranges or just in general potential reversal levels.
Multi Timeframe & Multi symbol: The bands work on very low TF as well as High TF, though on HTF it might be limited by the MA length settings and the historical data of the symbol. It is important to note that each symbol and market type will have its own ideal MA and Bands settings.
Multi Bands Confluence: Same as you would use a short and long MA in a single setup, you can do the same with the bands and the confluence of levels can be very accurate.
Multi Timeframe Confluence: One of the best ways to use the bands so far is by using it in confluence with itself in other TFs, when price moves sharply into a confluent level given by multiple TFs, it is more likely for price to reverse there.
Most of the examples show a 200 SMA, but depending on what and how you are trading a shorter or longer MA might be a better fit for you. As well, if you are trading ranges, a VWMA might be much better, and if you are following a trend the EMA could be the better option.
I also want to make it clear that the bands can but are NOT meant to be a standalone indicator. They are meant to be used for confluence with other strategies, systems or indicators.
Oscillator: Which follows Normal Distribution?When doing machine learning using oscillators, it would be better if the oscillators were normally distributed.
So I analyzed the distribution of oscillators.
The value of the oscillator was divided into 50 groups each from 0 to 100.
ex) if rsi value is 45.43 -> group_44, 58.23 -> group_58
Ocscillators : RSI, Stoch, MFI, WT, RVI, etc....
Caution: The normal distribution was verified through an empirical formula.

RSI is in Normal Distribution?Does RSI Follow a Normal Distribution?
The value of RSI was converted to a value between 0~2, 2~4, ..., 98~100, and the number of samples was graphed.
The Z values are expressed so that the values corresponding to 30 and 70 of the RSI can be compared with the standard normal distribution.
Additionally, when using the RSI period correction function of the 'RSI Candle Advanced V2' indicator that I made before, it shows no change in standard deviation.
RSI는 정규분포를 따를까요
RSI의 값을 0~2, 2~4, ..., 98~100 사이 값으로 변환하고 그 표본 갯수를 그래프로 표현하였습니다.
Z 값은 RSI의 30, 70에 해당하는 값을 표준정규분포와 비교할 수 있도록 표현하였습니다.
추가적으로 제가 예전에 만들었던 'RSI Candle Advanced V2' 지표의 RSI 기간 보정 함수를 사용할 경우 표준편차의 변화가 없음을 보입니다.

Return Abnormality Score [SpiritualHealer117]The Return Abnormality Score indicator is designed to help traders identify potential reversals in price by detecting abnormal daily returns beyond a certain significance level. The indicator uses a normal cumulative distribution function to calculate the probability of the daily return and flags it when it exceeds the specified significance level.
Traders can use this indicator by monitoring the abnormality score. If the daily return is negative, the probability is multiplied by a negative number. Therefore, if the abnormality score goes above the positive threshold, it suggests that the price is oversold, while if it goes below the negative threshold, it indicates that the price is overbought. It can also be helpful for spotting bear or bull traps due to their irregular behavior.
Depending on the trader's preference, the indicator can be smoothed or unsmoothed.
This indicator should be paired with other technical analysis tools like SSL Hybrid for trend confirmation, and proper risk management strategies.

Expected Move w/ Volatility Panel (advanced) [Loxx]This indicator shows the expected range of movement of price given the assumption that price is log-normally distributed. This includes 3 multiples of standard deviation and 1 user selected level input as a multiple of standard deviation. Expected assumes that volatility remains static on the next bar. In reality, this may or may not be the case, so use caution when making broad assumptions about the levels shown when using this indicator. However, these levels match the same levels on Loxx's backtests and Multi-Panel indicator. These static levels are used as the take profit targets and stoploss on all Loxx's scripts previously posted.
This indicator can be be used on all timeframes, but the internal timeframe must be higher than the current timeframe or an error is thrown. The purpose for internal MTF is so that you can track the deviation range from higher timeframes on lower timeframes. When "current bar" is selected, this indicator will change with live prices changes. This is useful if you wish to enter a trade before the current bar closes and need to know the deviation ranges before the close. Current bar is also useful to see the past ranges of literally that bar. When "past bar" is selected, then the values shown on the current bar are values that were calculated on the last bar. The previous bar setting is useful to track price changes with the assumption that you entered a trade at the close of the previous bar. The default set to the previous bar. (careful, this default setting won't match Loxx's Muti-Panel tool since the Multi-Panel is built using the current bar. To make them match, you must change this setting to current bar)
I've included the ability for you to smooth the output around a moving average. Included are Loxx's Moving Averages. There are 41 to choose from. See more details here:
Smoothing applied yielding Keltner Channels
Also included are various UI options to manipulate line styling and colors.
Volatility Panel
Shows information about user selected volatility included confidence range of the chosen volatility. The following volatility types are included with additional volatility types to added in future releases.
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility .
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility . That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Chi-squared Confidence Interval:
Confidence interval of volatility is calculated using an inverse CDF of a Chi-Squared Distribution. You can change the volatility input used to either realized, upper confidence interval, or lower confidence interval. This is included in case you'd like to see how far price can extend if volatility hits it's upper or lower confidence levels. Generally, you'd just used realized volatility , so I wouldn't change this setting.
Inverse CDF of a Chi-Squared Distribution
The chi-square distribution is a one-parameter family of curves. The parameter ν is the degrees of freedom.
The icdf of the chi-square distribution is
x=F^−1(p∣ν) = {x:F(x∣ν) = p}
where
p=F(x∣ν)= ∫ (t^(v-2)/2 * e^t/2) / (2^(v/2) / Γ(v/2))
ν is the degrees of freedom, and Γ( · ) is the Gamma function. The result p is the probability that a single observation from the chi-square distribution with ν degrees of freedom falls in the interval .
Related Indicators
Multi-Panel: Trade-Volatility-Probability
Variety Distribution Probability Cone

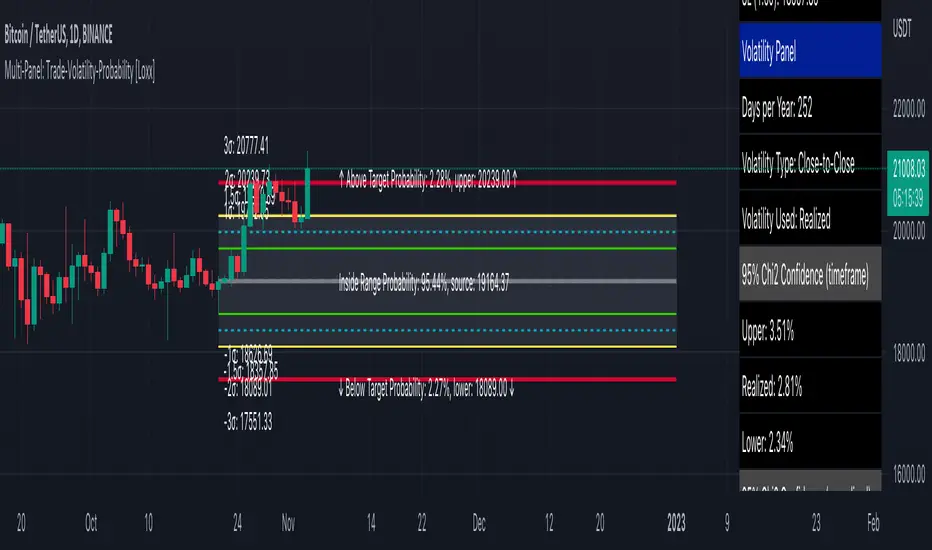
Multi-Panel: Trade-Volatility-Probability [Loxx]Multi-Panel: Trade-Volatility-Probability shows user selected and volatility-based price levels and probabilities on the chart. This is useful for both options and all styles of up/down trading methods that rely on volatility.
Trading Panel: Shows trading information to take profits and stop-loss based on multiples of volatility. Also shows equity inputs by the user to calculate optimal position size
Key things to note about the Trading Panel
-Trade side: Long or short. you change this this to change the take profit and SL levels in displayed on the table to be used w/ up/down trading styles that rely on volatility stops
-Account size: User enters total balance available for trade
-Risk: Total % of account size you're willing to lose should the SL be hit
-Position size: Size of the position given the SL and your preferred Risk
-Take profit/Stop loss levels: Based on multipliers selected by the user in settings. These shouldn't be changed unless you really know what you're doing with volatility stops
-Entry: Source price. can be 1 of 37 different prices. See Loxx's Expanded Source Types:
Volatility Panel: Shows information about the volatility the user selected to be used to take profit/stop-loss/range calculations. Volatility types included are:
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility. That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Chi-squared Confidence Interval:
Confidence interval of volatility is calculated using an inverse CDF of a Chi-Squared Distribution. You can change the volatility input used to either realized, upper confidence interval, or lower confidence interval. This is included in case you'd like to see how far price can extend if volatility hits it's upper or lower confidence levels. Generally, you'd just used realized volatility, so I wouldn't change this setting.
Inverse CDF of a Chi-Squared Distribution
The chi-square distribution is a one-parameter family of curves. The parameter ν is the degrees of freedom.
The icdf of the chi-square distribution is
x=F^−1(p∣ν) = {x:F(x∣ν) = p}
where
p=F(x∣ν)= ∫ (t^(v-2)/2 * e^t/2) / (2^(v/2) / Γ(v/2))
ν is the degrees of freedom, and Γ( · ) is the Gamma function. The result p is the probability that a single observation from the chi-square distribution with ν degrees of freedom falls in the interval .
Additional notes on Volatility Panel
-Shows both current timeframe volatility per candle at whatever date backward you select
-Shows annualized volatility basaed on selected days per year and per bar volatility; this is automaitcally caulculated no matter the timeframe used. This means that it'll calculate annualized volatility for the current candle even on the 1 second timeframe. Days per year should be 252 for everything but cryptocurrency; however, for all types of tradable assets, anything over the 3 day timeframe will calculate on 365 days.
Probability Panel
This panel shows the probability levels of a user selected upper and lower price boundary. This includes the inside range of volatility between the lower and upper price levels and the outside probability below the lower price level and above the upper price level. These values are calculated using the CDF (cumulative density function) of a normal distribution. In simpler terms, CDF returns area under a bell curve between two points left and right, or for our purposes, high and low. This yeilds the probabilities you see in the Probability Panel. See the following graphic to visualize how this works:
The red line is the entry bar; the yellow line is the "mean" but in this case just the chosen source price.
Other things to know
You can turn on/off all labels and levels and fills
normsinvLibrary "normsinv"
Description:
Returns the inverse of the standard normal cumulative distribution.
The distribution has a mean of zero and a standard deviation of one; i.e.,
normsinv seeks that value z such that a normal distribtuion of mean of zero
and standard deviation one is equal to the input probability.
Reference:
github.com
normsinv(y0)
Returns the inverse of the standard normal cumulative distribution. The distribution has a mean of zero and a standard deviation of one.
Parameters:
y0 : float, probability corresponding to the normal distribution.
Returns: float, z-score
cndevLibrary "cndev"
This function returns the inverse of cumulative normal distribution function
Reference:
The Full Monte, by Boris Moro, Union Bank of Switzerland . RISK 1995(2)
CNDEV(U)
Returns the inverse of cumulative normal distribution function
Parameters:
U : float,
Returns: float.
ctndLibrary "ctnd"
Description:
Double precision algorithm to compute the cumulative trivariate normal distribution
found in A.Genz, Numerical computation of rectangular bivariate and trivariate normal
and t probabilities”, Statistics and Computing, 14, (3), 2004. The cumulative trivariate
normal is needed to price window barrier options, see G.F. Armstrong, Valuation formulae
or window barrier options”, Applied Mathematical Finance, 8, 2001.
References:
link.springer.com
www.tandfonline.com
citeseerx.ist.psu.edu
The Complete Guide to Option Pricing Formulas, 2nd ed. (Espen Gaarder Haug)
CTND(LIMIT1, LIMIT2, LIMIT3, SIGMA1, SIGMA2, SIGMA3)
Returns the Cumulative Trivariate Normal Distribution
Parameters:
LIMIT1 : float,
LIMIT2 : float,
LIMIT3 : float,
SIGMA1 : float,
SIGMA2 : float,
SIGMA3 : float,
Returns: float.

norminvLibrary "norminv"
Description:
An inverse normal distribution is a way to work backwards
from a known probability to find an x-value. It is an informal term and
doesn't refer to a particular probability distribution. Returns the
value of the inverse normal distribution function for a specified value,
mean, and standard deviation.
Reference:
github.com
support.microsoft.com
norminv(x, mean, stdev)
Returns the value of the inverse normal distribution function for a specified value, mean, and standard deviation.
Parameters:
x : float, The input to the normal distribution function.
mean : float, The mean (mu) of the normal distribution function
stdev : float, The standard deviation (sigma) of the normal distribution function.
Returns: float.

cndLibrary "cnd"
Cumulative Normal Distribution
CND1(x)
Returns the Cumulative Normal Distribution (CND) using the Hart (1968) method. (preferred method, 14-18 decimal accuracy)
Parameters:
x : float,
Returns: float.
CND2(x)
Returns the Cumulative Normal Distribution (CND) using the Abromowitz and Stegun (1974) Polynomial Approximation.
Parameters:
x : float,
Returns: float.
CND3(x)
Returns the Cumulative Normal Distribution (CND) using Newton-Cotes method, Boole’s rule
Parameters:
x : float,
Returns: float.
One-Sided Gaussian Filter w/ Channels [Loxx]One-Sided Gaussian Filter w/ Channels is a Gaussian Moving Average that is calculated using a Fibonacci weighting function. Keltner channels have been added to show zones of exhaustion. A better name would be "Half Gaussian bell weighted" or "Half normal distribution weighted" indicator, since the weights for calculation of the average (similar to linear weighted average) are taken from a normal distribution curve like function--but only the half of the curve is used for calculation.
Information of the Gaussian distribution can be found here : en.wikipedia.org and once you take a look at the standard normal distribution curve, it will be much clearer what is exactly done in this indicator.
After the Gaussian Filter is applied to the source input, an Ehlers' 2-Pole Super Smoother is applied to reduce noise without significant lag.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Is the Bollinger Bands assumption wrong?Bollinger Bands are the result of the assumption that closing prices will follow a normal distribution.
However, when I actually calculated the probability, the closing price does not follow a normal distribution.
According to the normal distribution, the probability that Z > 2 should be 2.2%, but on the chart, the probability is 6~9%.
Can we get a useful value for Bollinger Bands that we can use in our strategy?
We can measure volatility, but can we judge volatility based on a fixed value?
To the right of each Bollinger band value, the probability that the price is above the band is displayed.
The script is simply annotated with how each probability is calculated.

Probability Distribution HistogramProbability Distribution Histogram
During data exploration it is often useful to plot the distribution of the data one is exploring. This indicator plots the distribution of data between different bins.
Essentially, what we do is we look at the min and max of the entire data set to determine its range. When we have the range of the data, we decide how many bins we want to divide this range into, so that the more bins we get, the smaller the range (a.k.a. width) for each bin becomes. We then place each data point in its corresponding bin, to see how many of the data points end up in each bin. For instance, if we have a data set where the smallest number is 5 and the biggest number is 105, we get a range of 100. If we then decide on 20 bins, each bin will have a width of 5. So the left-most bin would therefore correspond to values between 5 and 10, and the bin to the right would correspond to values between 10 and 15, and so on.
Once we have distributed all the data points into their corresponding bins, we compare the count in each bin to the total number of data points, to get a percentage of the total for each bin. So if we have 100 data points, and the left-most bin has 2 data points in it, that would equal 2%. This is also known as probability mass (or well, an approximation of it at least, since we're dealing with a bin, and not an exact number).
Usage
This is not an indicator that will give you any trading signals. This indicator is made to help you examine data. It can take any input you give it and plot how that data is distributed.
The indicator can transform the data in a few ways to help you get the most out of your data exploration. For instance, it is usually more accurate to use logarithmic data than raw data, so there is an option to transform the data using the natural logarithmic function. There is also an option to transform the data into %-Change form or by using data differencing.
Another option that the indicator has is the ability to trim data from the data set before plotting the distribution. This can help if you know there are outliers that are made up of corrupted data or data that is not relevant to your research.
I also included the option to plot the normal distribution as well, for comparison. This can be useful when the data is made up of residuals from a prediction model, to see if the residuals seem to be normally distributed or not.

ema exhaustion (exa)The exa is an oscillator that combines fisher transform with distance from moving average and it is based on a theory that exhaustion can be derived from how far price is able to extend from a moving average, on average.
The fisher transform converts price into a gaussian normal distribution, also known as a bell curve {1}. A normal distribution is a type of probability distribution for a real-valued random variable {2}. Applying this method to the price of an asset can help to identify probabilities, but it will never identify certainties.
‘exa’ is an abbreviation for ema exhaustion. It can be used to identify when price is probable to revert to the mean but I prefer using it to confirm entries that are signaled following a reversion to the mean (aka buying the dip in bull markets). When price gets oversold into support, in a bull trend, then that can provide a good opportunity to enter long. However that isn’t necessarily the case when the same metrics indicate oversold conditions in a bear trend. In this situation the exa is best suited for identifying profit taking opportunities on shorts.
The default settings are a 9 lookback period and a 50 ema. By default signals will be derived from how far price is from the 50 ema relative to the probable distribution of the last 9 periods. If the exa is above 2, or below -2, then the price is in the 80th percentile of the prior 9 candles. Being outside of 3, or -3, represents the 90th percentile and 4, or -4, represents the 95th percentile.
Those ranges will never indicate a necessity of reverting to the mean, but they will indicate a higher and higher probability. I prefer to use this oscillator in combination with an indicator(s) that identifies the trend. When the oscillator reaches -2 in a bull trend then it can confirm long entry signals, whereas if it reaches +2 in a bull trend then it can be used to confirm signals to take profit.
Crossovers are especially significant because they indicate a shift in the tide. When the exa reaches 2 without crossing over then it is very much in a position to move to 3 or 4+. When it crosses above 2 then it is an indication that price is extended from the mean and exhausted.
This is certainly not a situation that implies price will revert to the mean, it simply provides confirmation.
The default settings are what I have been finding most effective personally, however that is mostly a function of the trend following tools that I use. The same principles should apply with all settings and I would encourage users to experiment with various lookback periods and emas.
{1} www.investopedia.com
{2} en.wikipedia.org